Chapter 3 The power of rich, structured metadata
The previous chapter defined the features of an advanced data discoverability and dissemination solution. What enables such a solution is not only the algorithms and technology, but also the quality of the metadata available to enable them. Metadata is defined as “… structured information that describes, explains, locates, or otherwise makes it easier to retrieve, use or manage that resource” (Data thesaurus, NIH, https://nnlm/gov/data/thesaurus) Metadata must be findable by machines and usable by humans. This chapter describes what metadata are needed, and how they can be organized and improved to fully enable the search and recommender tools. The metadata must be rich and structured. To make them rich, machine learning can be used. To ensure consistent structure, the use of metadata standards and schemas is highly recommended. In this chapter, we build the case for rich, augmented, structured metadata and for the adoption of metadata standard and schemas. The second part of this Guide will provide a detailed description of each recommended standard or schema, for different data types.
3.1 Rich metadata
Rich metadata means detailed and comprehensive metadata. Rich metadata are beneficial to both the users and the providers (producers and curators) of data.
3.1.1 Benefits for data users
Being provided with rich metadata helps data users:
- Find data of interest. The metadata provide much of the content that the search engine will be able to index and discover. The richer the metadata, the better the search engine will be able to help users identify relevant data.
- Understand what the data are measuring and how they have been created. Without a proper description of the data, the risk is high that a user will misunderstand and possibly misuse them, or simply decide not to make use of them.
- Assess the quality of the data, including their reliability, fitness for purpose, and consistency with other datasets when the purpose requires integration of multiple datasets.
3.1.2 Benefits for data producers
For the data producers, rich metadata will contribute to:
- Ensure transparency, auditability, and credibility of the data and of the derived products.
- Increase the visibility of the data, and thus the demand for, and use of the data.
- Reduce the cost of operating a data dissemination service by lowering the burden of responding to users’ requests for information.
- Support the preservation of institutional memory.
- Provide the meta-database needed to harmonize data collection methods and instruments, e.g., by providing convenient tools to compare variables across datasets. A compelling case for rich metadata for transparency and harmonization can be found in “The Struggle for Integration and Harmonization of Social Statistics in
a Statistical Agency - A Case Study of Statistics Canada” by Gordon Priest (2010).
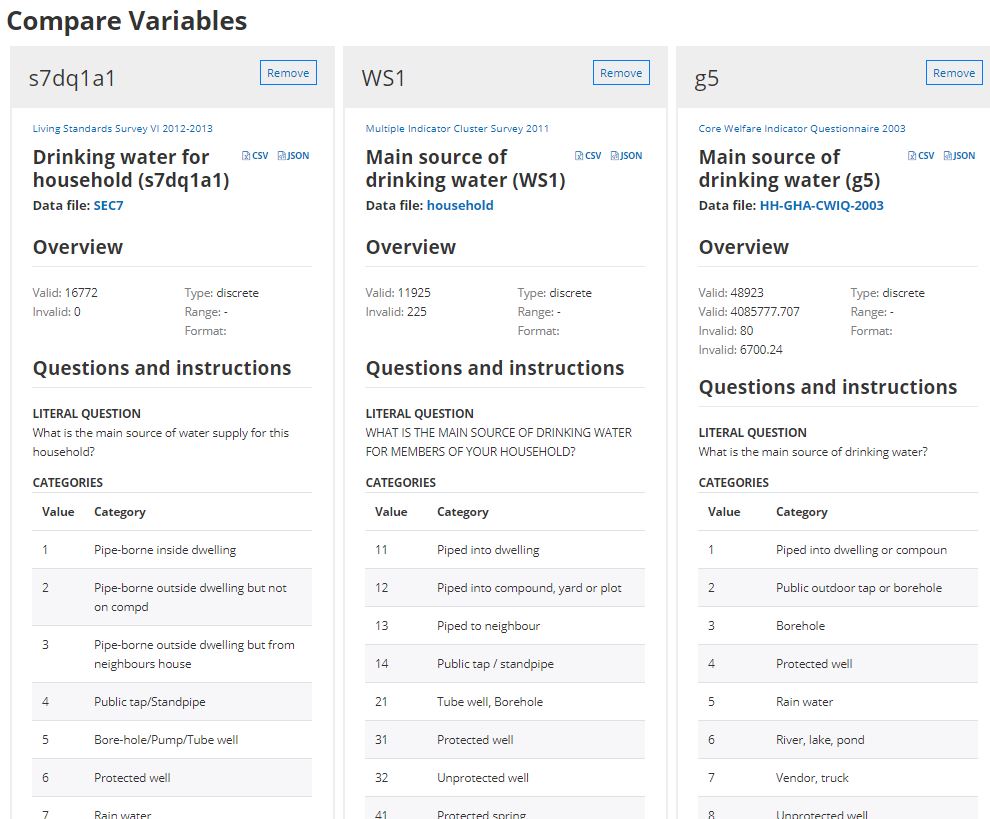
3.1.3 Scope of the metadata
What makes metadata “rich and comprehensive” is not always easy to define, and is specific to each data type. Microdata and geospatial datasets for example will require much more – and different– metadata than a document or an image. Metadata standards and schemas provide data curators with detailed lists of elements (or fields), specific to each data type, that must or may be provided to document a dataset. The metadata elements included in a standard or schema will typically cover cataloguing material, contextual information, and explanatory materials.
3.1.3.1 Cataloguing material
Cataloguing material includes elements such as a title, a unique identifier for the dataset, a version number and description, as well as information related to the data curation (including who generated the metadata and when, or where and when metadata may have been harvested from an external catalog). This information allows the dataset to be uniquely identified within a collection/catalog, and serves as a bibliographic record of the dataset, allowing it to be properly acknowledged and cited in publications.
3.1.3.2 Contextual information
Contextual information describes the context in which the data were collected and how they were put to use. It enables secondary users to understand the background and processes behind the data production. Contextual information should cover topics such as:
- What justified or required the data collection (the objectives of the data production exercise);
- Who or what was being studied;
- The geographic and temporal coverage of the data;
- Changes and developments that occurred over time in the data collection methodology and in the dataset, if relevant. For repeated cross-section, panel, or time series datasets, this may include information describing changes in the question text, variable labeling, sampling procedures, or others;
- What are the key output of the data collection, such as a publication, the design or implementation of a policy or project, etc.
- Problems encountered in the process of data collection, entry, checking, and cleaning;
- Other useful information on the life cycle of the dataset.
3.1.3.3 Explanatory material
Explanatory materials are the information that should be created and preserved to ensure the long-term functionality of a dataset and its contents. This applies mostly to microdata, geospatial data, and to some extent to tabulations and to time series and indicators databases. It is less relevant for images, videos, and documents. Explanatory materials include:
- Information about the data collection methods: This section should describe the instruments used and methods employed, and how they were developed. If applicable, details of the sampling design and sampling frames should be included. It is also useful to include information on any monitoring process undertaken during the data collection as well as details of quality controls.
- Information about the structure of the dataset: Key to this information is a detailed data dictionary describing the structure of the dataset, including information about relationships between individual files or records within the study. For example, it should include key variables required for unique identification of subjects across files (required to properly merge data files), the number of cases and variables in each file, and the number of files in the dataset. For relational models, the structure and relations between datasets records and elements should be described.
- Technical information: This information relates to the technical framework and should include the computer system used to generate the data and related files; the software packages with which the files were created.
- Variables and values, coding and classification schemes (for microdata and geospatial data): The documentation should contain an exhaustive list of variables in the dataset, including a complete explanation and full details about the coding and classifications used for the information allocated to those fields. It is especially important to have blank and missing fields explained and accounted for. It is helpful to identify variables to which standard coding classifications apply, and to record the version of the classification scheme used.
- Information about derived variables (for microdata and geospatial data, and tabulations): Many data producers derive new variables from original data. This may be as simple as grouping raw age (in years) data according to groups of years appropriate for the survey, or it may be much more complex and require the use of sophisticated algorithms. When grouped or derived variables are created, it is important that the logic for the grouping or derivation is clear. Simple grouping, such as for age, can be included within the data dictionary. More complex derivations require other means of recording the information. Sufficient supporting information should be provided to allow an easy link between the core variables used and the resultant variables. In addition, computer algorithms used to create the derivations should be saved together with information on the software.
- Weighting and grossing (for sample survey microdata): Weighting and grossing variables must be fully documented, with explanations of the construction of the variables and clear indications of the circumstances in which they should be used. The latter is particularly important when different weights are applied for different purposes.
- Data source: Details about the source from which the data is derived should be included. For example, when the data source consists of responses to survey questionnaires, each question should be carefully recorded in the documentation. Ideally, the text will include a reference to the generated variable(s). It is also useful to explain the conditions under which a question would be asked, including, if possible, the cases to which it applies and, ideally, a summary of response statistics.
- Confidentiality and anonymization: It is important to determine whether the data contains any confidential information on individuals, households, organizations, or institutions. If so, such information should be recorded together with any agreement on how to use the data, such as with survey respondents. Issues of confidentiality may restrict the analyses to be undertaken or results to be published, particularly if the data is to be made available for secondary use. If the data were anonymized to prevent identification, it is wise to record the anonymization procedure (taking care of not providing information that would enable a reverse-engineering of the procedure) and its impact on the data, as such modification may restrict subsequent analysis.
3.1.4 Controlled vocabularies
Metadata standards and schemas provide lists of elements with a description of the expected content to be captured in each element. For some elements, it may be appropriate to restrict the valid content to pre-selected options or “controlled vocabularies”. A controlled vocabulary is a pre-defined list of values that can be accepted as valid content for some elements. For example. a metadata element “data type” should not be populated with free text, but should make use of a pre-defined taxonomy of data types. The use of controlled vocabularies (for selected metadata elements) will be particularly useful to implement search and filter features in data catalogs (see section 3.1.1 of this Guide), and to foster inter-operability of data catalogs.
In library and information science, controlled vocabulary is a carefully selected list of words and phrases, which are used to tag units of information (document or work) so that they may be more easily retrieved by a search.Wikipedia
Controlled vocabularies can be specific to an agency, or be developed by a community of practice. For example, the list of countries and codes provided by the ISO 3166 can be used as a controlled vocabulary for a metadata element country or nation; the ISO 639 list of languages can be used as a controlled vocabulary for a metadata element language. Or the CESSDA topics classification can be used as a controlled vocabulary for the element topics found in most metadata schemas. When a controlled vocabulary is used in a metadata standard or schema, it is good practice to include an identification of its origin and version.
Some recommended controlled vocabularies are included in the description of the ISO 19139 standard for geographic data and services (see chapter 6). Most standards and schemas we recommend also include a topics element. Annex 1 provides a description of the CESSDA topics classification.
Ideally, controlled vocabulary will be developed in compliance with the FAIR principles for scientific data management and stewardship: Findability, Accessibility, Interoperability, and Reuse.
3.1.5 Tags
All metadata standards and schemas described in this guide include a tags element, even when this element is not part of a standard. This element enables the implementation of filters (facets) in data cataloguing applications, in a flexible manner. The tags metadata element is repeatable (meaning that more than one tag can be attached to a dataset) and contains two sub-elements to capture a tag (word or phrase), and the tag_group (if any) it belongs to.
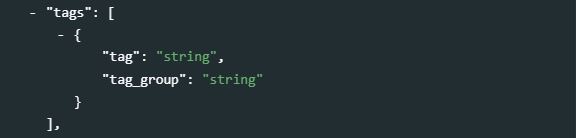
To illustrate the use of tags, let’s assume that a catalog contains datasets that are available freely, and others that are available for a fee. The catalog administrator may want to provide a filter (facet) in the user interface that would allow users to filter datasets based on their free or not free status. None of the metadata schemas we describe in the Guide contains an element specifically designed to indicate the “free” or “for a fee” nature of the data. But this information can be captured in a tag “Free” or “For a fee” that would be added to each dataset in the catalog, with a tag group that could be named “free_or_fee”. In R, this would be done as follows (for a “Free” dataset):
# ... ,
tags = list(
list(tag = "Free", tag_group = "free_or_fee")
)
# ... In the NADA catalog, a facet titled “Free or for a fee” can then be created based on the information found in the tags element where tag_group = “free_or_fee”.
3.2 Structured metadata
3.2.1 What structure?
Metadata should not only be comprehensive and detailed, they should also be organized in a structured manner, preferably using a standardized structure. Structured metadata means that the metadata are stored in specific fields (or elements) organized in a metadata schema. Standardized means that the list and description of elements are commonly agreed by a community of practice.
“A metadata schema is a system that defines the data elements needed to describe a particular object, such as a certain type of research data.” (Ten rules data discovert - add ref)
Some metadata standards have originated from academic data centers, like the Data Documentation Initiative (DDI), maintained by the Inter-University Consortium for Political and Social Research (ICPSR) at the University of Michigan. Other found their origins in specialized communities of practice (like the ISO 19139 for geospatial resources). The private sector also contributes to the development of standards, like the International Press Telecommunications Council (IPTC) standard developed by and for news media.
Metadata compliant with standards and schemas will typically be stored as JSON or XML files (described in Chapter 2), which are plain text files. The example below show how a simple free-text content would be structured and stored in JSON and XML formats, using metadata elements from the DDI Codebook metadata standard:
Free text version:
The Child Mortality Survey (CMS) was conducted by the National Statistics Office of Popstan from July 2010 to June 2011, with financial support from the Child Health Trust Fund (TF123_456).
Structured, machine-readable (JSON) version:
"title" : "Child Mortality Survey 2010-2011",
"alternate_title" : "CMS 2010-2011",
"authoring_entity": "National Statistics Office (NSO)",
"funding_agencies": [{"name":"Child Health Trust Fund (CHTF)", "grant":"TF123_456"}],
"coll_dates" : [{"start":"2010-07", "end":"2011-06"}],
"nation" : [{"name":"Popstan", "abbreviation":"POP"}]
} In XML format:
<titl>Child Mortality Survey 2010-2011</titl>
<altTitl>CMS 2010-2011</altTitl>
<rspStmt><AuthEnty>National Statistics Office</AuthEnty></rspStmt>
<fundAg abbr=CHTF>Child Health Trust Fund</fundAg>
<collDate date="2010-07" event="start"/>
<collDate date="2011-06" event="end"/>
<nation abbr="POP">Popstan</nation>All three versions contain (almost) the same information. In the structured version, we have added acronyms and the ISO country code. This does not create new information but will help make the existing information more discoverable and inter-operable. The structured version is clearly more suitable for publishing in a meta-database (or catalog). Organizing and storing metadata in such a structured manner will enable all kinds of applications. For example, when metadata for a collection of surveys are stored in a database, it becomes straightforward to apply filters (for example, a filter by country using the nation/name element) and targeted searches to answer questions like “What data are available that cover the month of December 2010?” or “What surveys did the CHTF sponsor?”.
3.2.2 Formats for structured metadata: JSON and XML
Metadata standards and schemas consist of structured lists of metadata fields. They serve multiple purposes. First, they help data curators generate complete and usable documentation of their datasets. Metadata standards that are intuitive and human-readable better serve this purpose. Second, they help generate machine-readable metadata that are the input to software applications like on-line data catalogs. Metadata available in open file formats like JSON (JavaScript Object Notation) and XML (eXtended Markup Language) are most suitable for this purposes.
Some international metadata standards like the Data Documentation Initative (DDI Codebook, for microdata), the ISO 19139 (for geospatial data), or the Dublin Core (a more generic metadata specification) are described and published as XML specifications. Any XML standard or schema can be “translated” into JSON, which is our preferred format (a choice we justify in the next section).
JSON and XML formats have similarities:
- Both are non-proprietary text files
- Both are hierarchical (they may contain values within values)
- Both can be parsed and used by many programming languages including R and Python
JSON files are however easier to parse than XML, easier to generate programmatically, and easier to read by humans. This makes them our preferred choice for describing and using metadata standards and schemas.
Metadata in JSON are stored as key/value pairs, where the keys correspond to the names of the metadata elements in the standard. Values can be string, numeric, boolean, arrays, null, or JSON objects (for a more detailed description of the JSON format, see www.w3schools.com). Metadata in XML are stored within named tags. The example below shows how the JSON and XML formats are used to document the list of authors of a document, using elements from the Dublin Core metadata standard.

In the documents schema, authors are documented in the metadata element authors which contains the following sub-elements: first_name, initial, last_name, and affiliation.
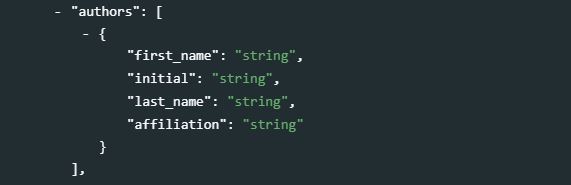
In JSON, this information will be stored in key/value pairs as follows.
"authors" : [
{"first_name" : "Dieter",
"last_name" : "Wang",
"affiliation": "World Bank Group; Fragility, Conflict and Violence"},
{"first_name" : "Bo",
"initial" : "P.J.",
"last_name" : "Andrée",
"affiliation": "World Bank Group; Fragility, Conflict and Violence"},
{"first_name" : "Andres",
"initial" : "F.",
"last_name" : "Chamorro",
"affiliation": "World Bank Group; Development Data Analytics and Tools"},
{"first_name" : "Phoebe",
"initial" : "G.",
"last_name" : "Spencer",
"affiliation":"World Bank Group; Fragility, Conflict and Violence"}
]In XML, the same information will be stored within named tags as follows.
<authors>
<author>
<first_name>Dieter</first_name>
<last_name>Wang</last_name>
<affiliation>World Bank Group; Fragility, Conflict and Violence</affiliation>
</author>
<author>
<first_name>Bo</first_name>
<initial>P.J.</initial>
<last_name>Andrée</last_name>
<affiliation>World Bank Group; Fragility, Conflict and Violence</affiliation>
</author>
<author>
<first_name>Andres</first_name>
<initial>E.</initial>
<last_name>Chamorro</last_name>
<affiliation>World Bank Group; Development Data Analytics and Tools</affiliation>
</author>
<author>
<first_name>Phoebe</first_name>
<initial>G.</initial>
<last_name>Spencer</last_name>
<affiliation>World Bank Group; Fragility, Conflict and Violence</affiliation>
</author>
</authors>3.2.3 Benefits of structured metadata
Metadata standards and schemas must be comprehensive and intuitive. They aim to provide comprehensive and granular lists of elements. Some standards may contain a very long list of elements. Most often, only a subset of the available elements will be used to document a specific dataset. For example, the elements of the DDI metadata standard related to sample design will be used to document sample survey datasets but will be ignored when documenting a population census or an administrative dataset. In all standards and schemas, most elements are optional, not required. Data curators should however try and provide content for all elements for which information is or can be made available.
Complying with metadata standards and schemas contributes to the completeness, usability, discoverability, and inter-operability of the metadata, and to the visibility of the data and metadata.
3.2.3.1 Completeness
When they document datasets, data curators who do not make use of metadata standards and schemas tend to focus on the readily-available documentation and may omit some information that secondary data users –and search engines– may need. Metadata standards and schemas provide checklists of what information could or should be provided. These checklists are developed by experts, and are regularly updated or upgraded based on feedback received from users or to accommodate new technologies.
Generating complete metadata will often be a collaborative exercise, as the production of data involves multiple stakeholders. The implementation of a survey, for example, may involve sampling specialists, field managers, data processing experts, subject matter specialists, and programmers. Documenting a dataset should not be seen as a last and independent step in the implementation of a data collection or production project. Ideally, metadata will be captured continuously and in quasi-real time during the entire life cycle of the data collection/production, and contributed by those who have most knowledge of each phase of the data production process.
Generating complete and detailed metadata may be seen as a burden by some organizations or researchers. But it will typically represent only a small fraction of the time and budget invested in the production of the data, and is an investment that will add much value to the data by increasing their usability and discoverability.
3.2.3.2 Usability
Fully understanding a dataset before conducting analysis should be a pre-requisite for all researchers and data users. But this will only be possible when the documentation is easy to obtain and exploit. Convenience to users is key. When using a geographic dataset for example, the user should be able to immediately find the coordinate reference system that was used. When using survey microdata, which may contain hundreds or thousands of variables, the user need to be able to immediately access information on a variable label, underlying question, universe, categories, etc. Structured metadata enables such “convenience”, as they can easily be transformed into bookmarked PDF documents, searchable websites, machine-readable codebooks, etc. The way metadata are displayed can be tailored to the specific needs of different categories of users.
3.2.3.3 Discoverability
Data discoverability is one of the main tasks, next to availability and interoperability, that public policy makers and implementers should take into due consideration in order to foster access, use and re-use of public sector information, particularly in case of open data. Users shall be enabled to easily search and find data they need for the most different purposes. That is clearly highlighted in the introduction statements of the INSPIRE Directive, where we can read that “The loss of time and resources in searching for existing (spatial) data or establishing whether they may be used for a particular purpose is a key obstacle to the full exploitation of the data available”. From Metadata and data portals/catalogues are essential assets to enable that data discoverability.
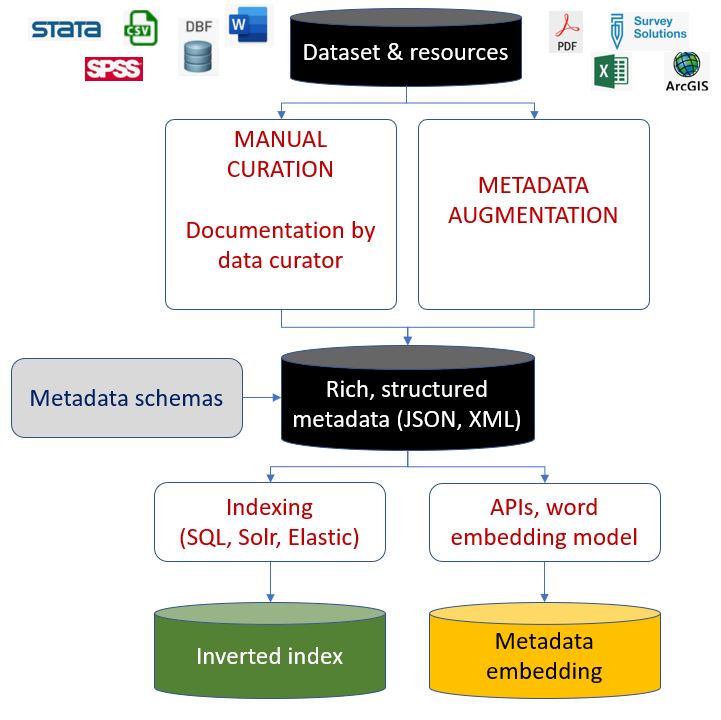
What matters is not only what metadata are provided as input to the search engines that matters, it is also how the metadata are provided. To understand the value of structured metadata, we need to take into consideration how search engines ingest, index, and exploit the metadata. In brief, the metadata will need to be acquired, augmented, analyzed and transformed, and indexed before they can be made searchable. We provide here an overview of the process, which is described in detail by D. Turnbull and J. Berryman in “Relevant Search: With applications for Solr and Elasticsearch” (2016).
Acquisition: Search engines like Google and Bing acquire metadata by crawling billions of web pages using web crawlers (or bots), with an objective to cover the entire web. Guidance is available to webmasters on how to optimize websites for visibility (see for example Google’s Search Engine Optimization (SEO) Starter Guide. The search tools embedded in specialized data catalogs have a much simpler task, as the catalog administrators and curators generate or control, and provide, the well-contained content to be indexed. In a cataloguing application like NADA, this content is provided in the form of structured metadata files saved in JSON or XML format. For textual data (documents), the content of the document (not only the metadata on the) can also be indexed. The process of acquisition/extraction of metadata by the search engine tool must preserve the structure of the metadata, in its original or in a modified form. This will be critical for optimizing the performance of the search tool and the ranking of query results (e.g., a keyword found in a document title may have more weight than the same keyword found in the document abstract), for implementing facets, or for providing advanced search options (e.g., search only in the “authors” metadata field).
Augmentation or enrichment: the content of the metadata can be augmented or enriched in multiple ways, often automatically (by extracting information from an external source, or using machine learning algorithms). Part of this augmentation process should happen before the metadata are submitted to the search engine. Other procedures of enrichment of the metadata may be implemented after acquisition of the metadata by the search engine tool. Metadata augmentation can have a significant impact on the discoverability of data. See the section “Augmented (enriched) metadata” below.
Analysis or transformation: The metadata generated by the data curator and by the augmentation process will mostly (not exclusively) consist of text. For the purpose of discoverability, some of the text has no value; words like “the”, “a”, it”, “with”, etc., referred to as stop words, will be removed from the metadata (multiple tools are available for this purpose). The remaining words will be converted to lowercase, may be submitted to spell checkers (to exclude or fix errors), and words will be stemmed or lemmatized. The stemming or lemmatization consist of converting words to their stem or root); this will among other transformations change plurals to singular and the conjugated forms of the verbs to their base form. Last, the transformed metadata will be tokenized, i.e. split into a list of terms (tokens). To enable semantic searchability, the metadata can also be converted into numeric vectors using natural language processing embedding models. These vectors will be saved in a database (such as ElasticSearch or Milvus) that will provide functionalities to measure similarity/distance between vectors. Section 1.8 below provide more information on text embedding and semantic searchability.
Indexing: The last phase of metadata processing is the indexing of the tokens. The index of a search engine is an inverted index, which will contain a list of all terms found in the metadata, with the following information (among other) attached to each term:
- The document frequency, i.e. the number of metadata documents where the word is found (a metadata document is the metadata related to one dataset).
- The identification of the metadata documents in which the term was found.
- The term frequency in each metadata document.
- The term positions in the metadata document, i.e. where the term is found in the document. This is important to identify colocations. When a user submits a query for “demographic transition” for example, documents where the two terms are found next to each other will be more relevant than documents where both terms appear but in different parts of the document.
Once the metadata has been acquired, transformed, and indexed, it is available for use via a user interface (UI). A data catalog UI will typically include a search box and facets (filters). The search engine underlying the search box can be simple (out-of-the-box full text search, looking for exact matches of keywords), or advanced (with semantic search capability and optimized ranking of query results). Basic full-text search do not provide satisfactory user experience, as we illustrated in the introduction to this Guide. Rich, structured metadata, combined with advanced search optimization tools and machine learning solutions, allow catalog administrators to tune the search engine, and implement advanced solutions including semantic searchability.
3.2.3.4 Interoperability
Data catalogs that adopt common metadata standards and schemas can exchange information including through automated harvesting and synchronization of catalogs. This allows them to increase their visibility, and to publish their metadata in hubs. Recommendations and guidelines for improved inter-operability of data catalogs are provided by the Open Archives Initiative.
Interoperability between data catalogs can be further improved by the adoption of common controlled vocabularies. For example, the adoption of the ISO country codes in country lists will guarantee that all catalogs will be able to filter dataset by country in a consistent manner. This will solve the issue of possible differences in the spelling of country names (e.g., one catalog referring to the Democratic Republic of Congo as Congo, DR, and another one as Congo, Dem. Rep.). It also solves issues of changing country names, e.g. Swaziland renamed as Eswatini in 2018). Controlled vocabularies are often used for “categorical” metadata elements like topics, keywords, data type, etc. Some metadata standards like the ISO 19139 for geospatial data include their own recommended controlled vocabularies. Ideally, controlled vocabularies are developed in accordance with FAIR principles (Findability, Accessibility, Interoperability, and Reuse of digital assets). “The principles emphasise machine-actionability (i.e., the capacity of computational systems to find, access, interoperate, and reuse data with none or minimal human intervention) because humans increasingly rely on computational support to deal with data as a result of the increase in volume, complexity, and creation speed of data.” (https://www.go-fair.org/fair-principles/)
The adoption of standards and schemas by software developers also contributes to the easy transfer of metadata across applications. For example, data capture tools like Survey Solutions by the World Bank and CsPro by the US Census Bureau offer options to export metadata compliant with the DDI Codebook standard; ESRI’s ArcGIS software export geospatial metadata in the ISO 19139 standard.
3.2.3.5 Visibility
Data cataloguing applications provide search and filtering tools to help users of the catalog identify data of interest. But not all users will start their search for data directly in specialized data catalogs; many will start their search in Google, Google Dataset Search, Bing, Yahoo! or another search engine.
Some search engines may provide users with a direct answer to their query, without transiting via the source catalog. This will be the case when the query can be associated with a specific indicator, time and location for which data are openly available or accessible via a public API. For example, a search for “population india 2020” on Google, will provide an answer first, followed by links to the underlying sources.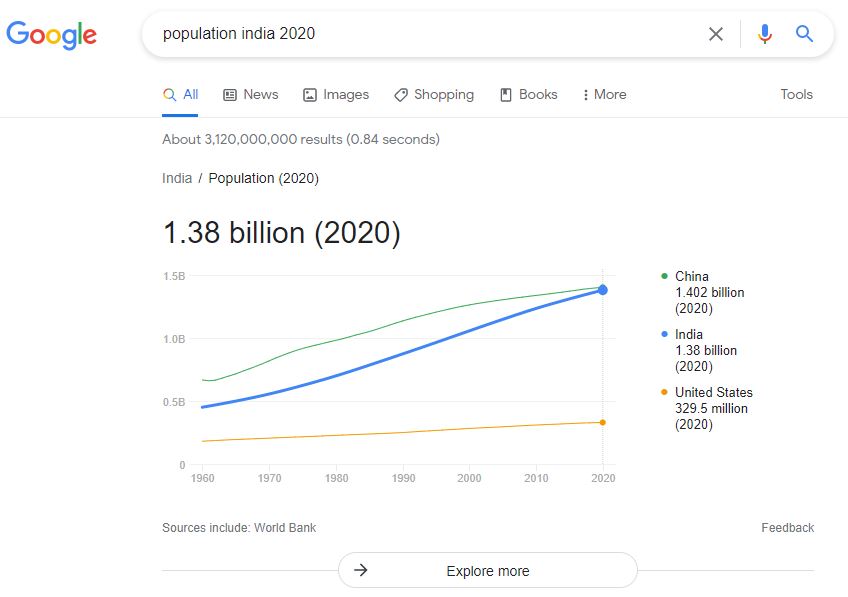
In some cases, the user may not be brought to the data catalog at all, if the catalog ranked low in the relevance order of the Google query results. User behavior data (2020) showed that “only 9% of Google searchers make it to the bottom of the first page of the search results”, and that “only .44% of searchers go to the second page of Google’s search results”. (source: https://www.smartinsights.com/search-engine-marketing/search-engine-statistics/)
It is thus critical to optimize the visibility of the content of specialized data catalogs in the lead search engines, Google in particular. This optimization process is referred to as search engine optimization or SEO. Wikipedia describes SEO as “the process of improving the quality and quantity of website traffic to a website or a web page from search engines. SEO targets unpaid traffic (known as”natural” or “organic” results) rather than direct traffic or paid traffic. (…) As an Internet marketing strategy, SEO considers how search engines work, the computer-programmed algorithms that dictate search engine behavior, what people search for, the actual search terms or keywords typed into search engines, and which search engines are preferred by their targeted audience. SEO is performed because a website will receive more visitors from a search engine when websites rank higher on the search engine results page.”
Because search engines crawl the web pages that are generated from databases (rather than crawling the databases themselves), your carefully applied metadata inside the database will not even be seen by search engines unless you write scripts to display the metadata tags and their values in HTML meta tags. It is crucial to understand that any metadata offered to search engines must be recognizable as part of a schema and must be machine-readable, which is to say that the search engine must be able to parse the metadata accurately. (For example, if you enter a bibliographic citation into a single metadata field, the search engine probably won’t know how to distinguish the article title from the journal title, or the volume from the issue number. In order for the search engine to read those citations effectively each part of the citation must have its own field. (…) Making sure metadata is machine-readable requires patterns and consistency, which will also prepare it for transformation to other schema. (This is far more important than picking any single metadata schema. (…) From the blog post “Metadata, Schema.org, and Getting Your Digital Collection Noticed” by Patrick Hogan (https://www.ala.org/tools/article/ala-techsource/metadata-schemaorg-and-getting-your-digital-collection-noticed-3)
Guidelines for implementing SEO are provided by Google Search, Google Dataset Search, and other lead search engines. These guidelines are to be implemented not only by webmasters, but also by the developers of data cataloguing tools who should embed SEO into their software applications.
- Google Search Engine Optimization Starter Guide
- Google Dataset Search, Advanced SEO
- Bing webmaster Tools
An important element of SEO is the provision of structured metadata that can be exploited directly by the crawlers and indexers of search engines. This is the purpose of a set of schemas known as schema.org. In 2011 Google, Microsoft, Yandex, and Yahoo! created a common set of schemas for structured data markup on web pages with the aim of helping search engines to better understand websites. An alternative to schema.org is the DCAT (Data Catalog Vocabulary) metadata schema recommended by the W3C, also recognized by Google. “DCAT is a vocabulary for publishing data catalogs on the Web, which was originally developed in the context of government data catalogs such as data.gov and data.gov.uk (…)” (https://www.w3.org/TR/vocab-dcat-2/) Mapping augmented and structured metadata to the schema.org and/or DCAT standard is a critical element of such optimization. It will contribute significantly to the visibility of on-line data and metadata. Implementing such structured data markup in digital repositories is the responsibility of data librarians and of developers of data cataloguing applications.
3.3 Augmenting metadata
Detailed and complete metadata foster usability and discoverability of data. Augmentation of “enrichment” or “enhancement” of the metadata will therefore be beneficial. There are multiple ways metadata can be made richer, or augmented, programmatically and in a largely automated manner. Metadata can be extracted from external sources or from the data themselves.
Extraction from external sources
Metadata can be augmented by tapping into external sources related to the data being documented. For example, in a catalog of documents published in peer-reviewed journals, the Scimago Journal Rank (SJR) indicator could be extracted and added as an additional metadata element for each document. This information can then be used by the catalog’s search engine to rank query results, by “boosting” the rank of documents published in prestigious journals.
Extraction from the data
Metadata can be extracted from the data themselves. What metadata can be extracted will be specific to each data type. Examples of metadata augmentation will be provided in the subsequent chapters. We mention a few below.
- For microdata: variable-level statistics (range of values, number of valid/missing cases, frequencies for categorical variables, summary statistics like means or standard deviations for continuous variables) can be extracted and stored as metadata. The DDI Codebook metadata standard provides elements for that purpose.
- For documents: information such as the country counts (how many times each country is mentioned) can be extracted automatically to fill out the metadata element related to geographic coverage. Natural language processing (NLP) models can be applied to automatically extract keywords or topics (e.g., using a Latent Dirichlet Allocation - LDA - topic model). Classification models can be applied to categorize documents by type.
Embeddings and semantic discovery
Previous sections of the chapter showed the value of rich and structured metadata to improve data usability and discoverability. Comprehensive and structured metadata are required to build and develop advanced and optimized lexical search engines (i.e. search engines that return results based on a matching of terms found in a query and in an inverted index). The richness of the metadata guarantees that the search engine will have all necessary “raw material” to identify datasets of interest. The metadata structure allows catalog administrators to tune their search engine (provided they use advanced solutions like Solr or ElasticSearch) to return and rank results in the most relevant manner. But this leaves one issue unsolved: the dependency on keyword matching. A user interested in datasets related to malnutrition for example will not find the indicators on Prevalence of stunting and Prevalence of wasting that the catalog may contain, unless the keyword “malnutrition” was included in these indicators’ metadata. Smarter search engines will be able to “understand” users intent, and identify relevant data based not only on a keyword matching process, but also on the semantic closeness between a query submitted by thea user and the metadata available in the database. The combination of rich metadata and natural language processing (NLP) models can solve this issue, by enabling semantic searchability in data catalogs.
To enable a semantic search engine (or a recommender system), we need a way to “quantify” the semantic content of a query submitted by the user and the semantic content the metadata associated with a dataset, and to measure the closeness between them. This “quantitative” representation of semantic content can be generated in the form of numeric vectors called embeddings. “Word embedding is a term used for the representation of words for text analysis, typically in the form of a real-valued vector that encodes the meaning of the word such that the words that are closer in the vector space are expected to be similar in meaning.” (Jurafsky, Daniel; H. James, Martin (2000)). These vectors will typically have a large dimension, with a length of 100 or more. They can be generated for a word, a phrase, or a longer text such as a paragraph or a full document. They are calculated using models like word2vec (Mikolov et al., 2013) or other. Training such models require a large corpus of hundreds of thousands or millions of documents. Pre-trained models and APIs are available that allow data catalog curators to generate embeddings for their metadata and, in real time, for queries submitted by users.
Practically, embeddings are used as follows: metadata (or part of the metadata) associated with a dataset are converted into a numeric vector using a pre-trained embedding model. These embeddings are stored in a database. When a user submits a search query (which can be a term, a phrase, or even a document), the query is analyzed and enhanced (stop words are removed, spelling errors may be fixed, language detection and automatic translation may be applied, and more), then transformed into a vector using the same pre-trained model that was used to generate the metadata vectors. The metadata vectors that have the shortest distance (typically the cosine distance) with the query vector will be identified. The search engine will then return a sorted list of datasets having the highest semantic similarity with the query, or the distance between vectors will be used in combination with other criteria to rank and return results to the user. The fast identification of the closest vectors requires a specialized and optimized tool like the open source Milvus application.
- For geospatial data: bounding boxes (i.e. the extent of the data) can be derived from the data files.
- For photos taken by digital cameras: metadata such as the date and time the photo was taken and possibly the geographic location can be extracted from the EXIF metadata generated by digital cameras and stored in the image file. Also, machine learning models allow image labeling, face detection, text detection and recognition to be applied at low cost (using commercial solutions like Google Vision or Amazon Rekognition among others).
- For videos and audio files, machine learning models of speech-to-text API solutions can be used to automatically generate transcripts (see for example Amazon Transcribe, Google Cloud Speech-to-Text, Microsoft Azure Speech to Text, or rev.ai). The content of the transcripts can then be indexed in search engines, making the content of video and audio files more discoverable.
- For programs and scripts: a parsing of the commands used in the script may be used to derive information on the methods applied.
- For all types: user-defined tags can be added, possibly generated by machine learning classification algorithms.
3.4 Recommended standards and schemas
The standards and schemas we recommend and describe in this guide are the following:
| Data type | Standard or schema |
|---|---|
| Documents | Dublin Core Metadata Initiative (DCMI), MARC |
| Microdata | Data Documentation Initiative 2.5 (Codebook) |
| Geographic datasets and services | ISO 19110, ISO19115, ISO19119, ISO 19139 |
| Time series, Indicators | Custom-designed schema |
| Statistical tables | Custom-designed schema |
| Photos / Images | IPTC (for advanced use) or Dublin Core augmented |
| Audio files | Dublin Core augmented with AudioObject from schema.org |
| Videos | Dublin Core augmented with VideoObject from schema.org |
| Programs and scripts | Custom-designed schema |
| External resources | Dublin Core |
| All data types | schema.org and DCAT (used for search engine optimization purpose, not as the primary schema to document resources) |
Note on SDMX: The metadata standards and schemas described in the Guide do not include the Statistical Data and Metadata eXchange (SDMX) standard sponsored by a group of international organisations. Although SDMX includes a metadata component, it is intended to support machine-to-machine data exchange, not data documentation and discoverability. SDMX and the metadata standards and schemas we describe in the Guide could –and should– be made inter-operable.
3.4.1 Documents
Documents are bibliographic resource of any type, such as books, working papers and papers published in scientific journals, reports, manuals, and other resources consisting mainly of text. Document libraries have along tradition of using structured metadata to manage their collections, which dates back from before the days this was computerized. Multiple standards are available. The Dublin Core Metadata Initiative specification (DCMI) provides simple and flexible option. The MARC standard (MAchine-Readable Cataloging) standard used by the United States Library of Congress is another, more advanced one. The schema we describe in this Guide make is the DCMI complemented by a few elements inspired by the MARC standard.
3.4.2 Microdata
Microdata are unit-level data on a population of individuals, households, dwellings, facilities, establishments or other. Microdata are typically obtained from surveys, censuses, or administrative recording systems. To document microdata, the Data Documentation Initiative (DDI) Alliance has developed the DDI metadata standard. “The Data Documentation Initiative (DDI) is an international standard for describing the data produced by surveys and other observational methods in the social, behavioral, economic, and health sciences. DDI is a free standard that can document and manage different stages in the research data lifecycle, such as conceptualization, collection, processing, distribution, discovery, and archiving. Documenting data with DDI facilitates understanding, interpretation, and use – by people, software systems, and computer network.” (Source: https://ddialliance.org/, accessed on 7 June 2021)
The DDI standard comes in two versions: DDI Codebook and DDI Lifecycle.
- DDI-Codebook is a light-weight version of the standard. Its elements include descriptive content for variables, files, source material, and study level information. The standard is designed to support the discovery, preservation, and the informed use of data.
- DDI Lifecycle is designed to document and manage data across the entire life cycle, from conceptualization to data publication, analysis and beyond. It encompasses all of the DDI-Codebook specification and extends it.
In this Guide, which focuses on the use of matadata standards for documentation, cataloguing and dissemination purposes, we recommend the use of the DDI Codebook which is much easier to implement than the DDI LifeCycle. DDI Codebook provides all necessary elements needed for our purpose of improving data discoverability and usability.
3.4.3 Geographic datasets, data structures, and data services
Geographic data identify and depict geographic locations, boundaries and characteristics of features on the surface of the earth. Geographic datasets include raster and vector data files. More or more data is disseminated not in the form of datasets, but in the form of geographic data services mainly via web applications. The ISO Technical Committee on Geographic Information/Geomatics (ISO/TC211), created a set of metadata standards to describe geographic datasets (ISO 19115), the geographic data structures of vector data (ISO 19110), and geographic data services (ISO 19119). These ISO standards are also available as an XML specification, the ISO 19139. In this Guide, we describe a JSON and simplified –but ISO-compatible– version of this complex schema.
3.4.4 Time series, indicators
Indicators are summary (or “aggregated”) measures related to a key issue or phenomenon and derived from a series of observed facts. For example, the school enrollment rate indicator can be obtained from survey or census microdata, and the GDP per capita indicator is the output of a complex national accounting process that exploits many sources. When an indicator is repeated over time at a regular frequency (annual, quarterly, monthly or other), and when the time dimension is attached to its values, we obtain a time series. National statistical agencies and many other organizations publish indicators and time series. Some well-known public databases of time series indicators include the World Bank’s World Development Indicators (WDI), the Asian Development Bank’s Key Indicators (KI), and the United Nations Statistics Division Sustainable Development Goals (SDG) database. Some databases provide indicators that are not time series, like the Demographic and Health Survey (DHS) StatCompiler. Time series and indicators must be published with metadata that provide information on their spatial and temporal coverage, definition, methodology, sources, and more. No international standard is available to document indicators and time series. The JSON metadata schema we describe in this guide was developed by compiling a list of metadata elements found in international indicators databases, complemented with elements from other metadata schemas.
3.4.5 Statistical tables
Statistical tables (or cross tabulations or contingency tables) are summary presentations of data, presented as arrays of rows and columns that display numeric aggregates in a clearly labeled fashion. They are typically found in publications such as statistical yearbooks, census and survey reports, research papers, or published on-line. We developed the metadata schema presented in this Guide based on a review of a large collection of tables and of the 2015 W3C Model for Tabular Data and Metadata on the Web. This schema is intended to facilitate the cataloguing and discovery of tabular data, not to provide an electronic solution to automatically reproduce tables.
3.4.6 Images
The images we are interested in are photos and images available in electronic format. Some images are generated using digital cameras and are “born digital”. Others may have been created by scanning photos, or using other techniques. Note that satellite and remote sensing imagery are not considered in this Guide as images, but as geospatial (raster) data which should be documented using the ISO 19139 schema. To document images, we suggest two options: the Dublin Core Metadata Initiative standard augmented by some ImageObject (from schema.org) elements as a simple option, and the IPTC standard for more advanced uses and users.
3.4.7 Audio
To document and catalog audio recordings, we propose a simple metadata schema that combines elements of the Dublin Core Metadata Initiative and of the AudioObject (from schema.org) schemas.
3.4.8 Videos
To document and catalog videos, we propose a simple metadata schema that combines elements of the Dublin Core Metadata Initiative and of the VideoObject (from schema.org) schemas.
3.4.9 Programs and scripts
We are interested in documenting and disseminating data processing and analysis programs and scripts. By “programs and scripts” we mean the code written to conduct data processing and data analysis, that results in the production of research and knowledge products including dublications, derived datasets, visualizations, or other. These scripts are produced using statistical analysis software or programming languages like R, Python, SAS, SPSS, Stata or equivalent. There are multiple reasons to invest in the documentation and dissemination of reproducible and replicable data processing and analysis (see chapter 12). Increasingly, the dissemination of reproducible scripts is a condition imposed by peer-reviewed journals to authors of papers they publish. Data catalogs should be the go-to place for those who look for reproducible research and examples of good practice in data analysis. As no international metadata schema is available to document and catalog scripts, we developed a schema for this purpose.
3.4.10 External resources
External resources are files and links that we may want to attach to a dataset’s published metadata in a data catalog. When we publish metadata in a catalog, what is published is only the textual documentation contained in the JSO or XML metadata file. Other resources attached to a dataset (such as the questionnaire for a survey, technical or training manuals, tabulations, reports, possibly micro-data files, etc.) are not included in these metadata, but also constitute important materials for data users. All these resources are what we consider as external resources (“external” to the schema-compliant metadata), which need to be catalogued and (for most of them) published with the metadata. A simple metadata schema, based on the Dublin Core, is used to provide some essential information on these resources.
3.5 Search engine optimization: schema.org
The standards and schemas we recommend are lists of elements that have been tailored for each data type. The importance of structured and rich metadata has been described. Specialized metadata standards will foster comprehensiveness and discoverability in specialized catalog, and help build optimized data discovery suystems. But it is also critical to ensure the visibility and discoverability of the metadata in generic search engines, which are not built around the same schemas. The web makes use of its own schemas: schema.org. To ensure SEO, the specialized schemas should be mapped to it.
3.5.1 The basics of search engine optimization
Data catalogs must be optimized to improve the visibility and ranking of their content in search engines, including specialized search engines like Google’s Dataset Search. The ranking of web pages by Google and other lead search engines is determined by complex, proprietary, and non-disclosed algorithms. The only option for a web developer to ensure that a web page appears on top of the Google list of results is to pay for it, publishing it as a commercial ad. Otherwise, the ranking of a web page will be determined by a combination of known and unknown criteria. “Google’s automated ranking systems are designed to present helpful, reliable information that’s primarily created to benefit people, not to gain search engine rankings, in the top Search results.” (Google Search Central) But Google, Bing and other search engines provide web developers with some guidance and recommendations on search engine optimization (SEO). See for example the Google Search Central website where Google publish “Specific things you can do to improve the SEO of your website”.
Improving the ranking of catalog pages is a shared responsibility of data curators and catalog developers and administrators. Data curators must pay particular attention to providing rich, useful content in the catalog web pages (the HTML pages that describe each catalog entry). To identify relevant results, search engines index the content of web pages. Datasets that are well documented, i.e. those published with rich and structured metadata, will thus have a better chance to be discovered. Much attention should be paid to some core elements including the dataset title, producer, description (abstract), keywords, topics, access license, and geographic coverage. In Google Search Central’s terms, curators must “create helpful, reliable, people-first content” (not search engine-first content) and “use words that people would use to look for your content, and place those words in prominent locations on the page, such as the title and main heading of a page, and other descriptive locations such as alt text and link text.*
Developers and administrators of cataloguing applications must pay attention to other aspects of a catalog that will make it rank higher in Google and other search engine results:
- Ensuring that a data catalog delivers a good experience to users (see Understanding page experience in Google Search results), which among other things involves:
- Catalog pages that load fast
- Catalog pages that are mobile-friendly. A data catalog should thus be built with a responsive design.
- Provide secure connection by serving the catalog over HTTPS (see more information, see for example https://web.dev/enable-https/)
- Embedding structured data in the catalog’s HTML pages. The HTML pages in a data catalog are mostly the pages that will make the metadata specific to an entry visible to the user. These pages are automatically generated by the cataloguing application, by extracting and formatting the metadata stored in the catalog’s database. Structured data is information that will be included in these HTML pages (but not shown to the user) to help Google understand the content of the page. The use of structured data only applies to certain types of content, including datasets. The use of structured data influences not only the ranking of a page, but also the way information on the page will be displayed by Google. The next section is dedicated to this.
Last, Google will “reward” popular websites, i.e. websites that are frequently visited and to which many other influent and popular websites provide links. Google’s recommendation is thus to “tell people about your site. Be active in communities where you can tell like-minded people about your services and products that you mention on your site.”
A helpful and detailed self-assessment list of items that data curators, catalog developers, and catalog administrators should pay attention to is provided by Google. Various tools are also available to catalog developers and administrators to assess the technical performance of their websites.
3.5.1.1 Structured data for rich results in Google
Structured data is information that is embedded in HTML pages that helps Google classify, understand, and display the content of the page when the page is related to a specific type of content. The information stored in the structured data does not impact how the page itself is displayed in a web browser; it only impacts the display of information on the page when returned by Google search results. The types of content to which structured metadata applies is diverse and includes items like job positings, cooking receipes, books, events, movies, math solvers, and others (see the list provided in Google’s Search Gallery). It also applies to resources of type dataset and image. In this context, a dataset can be any type of structured dataset including microdata, indicators, tables, and geographic datasets.
The structured data to be embedded in an HTML page consists of a set of metadata elements compliant with either the dataset schema from schema.org or W3C’s Data Catalog Vocabulary (DCAT) for datasets, and with the image schema from schema.org for images. For datasets, the schema.org schema is the most frequently used option.[^1]
3.5.1.2 schema.org
schema.org is a collection of schemas designed to document many types of resources. The most generic type is a “thing” which can be a person, an organization, an event, a creative work, etc. A creative work can be a book, a movie, a photograph, a data catalog, a dataset, etc. Among the many types of creative work for which schemas are available, we are particularly interested in the ones that correspond to the types of data and resources we recommend in this guide. This includes:
- DataCatalog: A data catalog is a collection of datasets.
- Dataset: A body of structured information describing some topic(s) of interest.
- MediaObject: A media object, such as an image, video, or audio object embedded in a web page or a downloadable dataset. This includes:
- ImageObject: An image file.
- AudioObject: An audio file.
- VideoObject: A video file.
- ImageObject: An image file.
- Book: A book.
- DigitalDocument: An electronic file or document.
The schemas proposed by schema.org have been developed primarily “to improve the web by creating a structured data markup schema supported by major search engines. On-page markup helps search engines understand the information on web pages and provide richer search results.” (from schema.org, Q&A) These schemas have not been developed by specialized communities of practice (statisticians, survey specialists, data librarians) to document datasets for preservation of institutional memory, to increase transparency in the data production process, or to provide data users with the “cook book” they may need to safely and responsibly use data. These schemas are not the ones that statistical organizations need to comply with international recommendations like the Generic Standard Business Process Model (GSBPM). But they play a critical role in improving data discoverability, as they provide webmasters and search engines with a means to better capture and index the content of web-based data platforms. Schemas from schema.org should thus be embedded in data catalogs. Data cataloguing applications should automatically map (some of) the elements of the specialized metadata standards and schemas they use to the appropriate fields of schema.org. Recommended mapping between the specialized standards and schemas and schema.org are not yet available. The production of such mappings, and the development of utilities to facilitate the production of content compliant with schema.org, would contribute to the objective of visibility and discoverability of data.
3.5.1.3 DCAT
DCAT describes datasets and data services using a standard model and vocabulary. It is organized in 13 “classes” (Catalog, Cataloged Resource, Catalog Record, Dataset, Distribution, Data Service, Concept Scheme, Concept, Organization/Person, Relationship, Role, Period of Time, and Location). Within classes, properties are used as metadata elements. For example, the class Cataloged Resource includes properties like title, description, resource creator; the class Dataset includes properties like spatial resolution, temporal coverage; many of these properties can easily be mapped to equivalent elements of the specialized metadata schemas we recommend in this Guide.
3.5.1.4 Practical implementation of structured data
The embedding of structured data into HTML pages must be automated in a data cataloguing tool. Data catalogs applications dynamically generate the HTML pages that display the description of each catalog entry. They do so by extracting the necessary metadata from the catalog database, and applying “transformations and styles” to this content to produce a user-friendly output that catalog visitors will view in their web browser. To embed structured data in these pages, the catalog application will (i) extract the relevant subset of metadata elements from the original metadata (e.g., from the DDI-compliant metadata for a micro-dataset), (ii) map these extracted elements to the schema.org or DCAT schema, and (iii) save it in the HTML page as a JSON-LD “hidden” component. Mapping the core elements of specialized metadata standards to the schema.org schema is thus essential to enable this feature. A mapping between the schema presented in this Guide and schema.org is provided in annex 2 of the Guide.
The screenshots below show an example of an HTML page for a dataset published in a NADA catalog, with the underlying code. The structured metadata is used by Google to display this information as a formatted, “rich result” in Google Dataset Search.
The HTML page as viewed by the catalog user - The web browser will ignore the embedded structured metadata when the HTML page is displayed. What users will see is entirely controlled by the catalog application.
The HTML page code (abstract) - The automatically-generated structured data can be seen in the HTML page code (or page source). This information is visible and processed by Google, Bing, and other search engine’s web crawlers. Note that the structured data, although not “visible” to users, can be made accessible to them via API. Other data cataloguing applications may be able to ingest this information; the CKAN cataloguing tool for example makes use of metadata compliant with DCAT or schema.org. Making the structured data accessible is one way to improve the inter-operability of data catalogs.
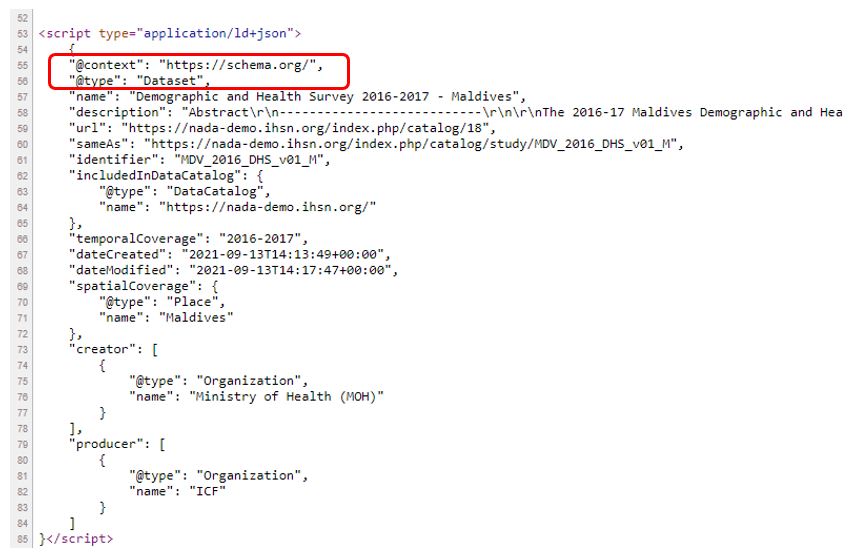
The result - Higher visibility/ranking in Google Dataset Search - The websites catalog.ihsn.org and microdata.worldbank.org are NADA catalogs, which embed schema.org metadata.
3.6 Where to find the schemas’ documentation
The most recent documentation of the schemas described in the Guide is available on-line at https://ihsn.github.io/nada-api-redoc/catalog-admin/#.
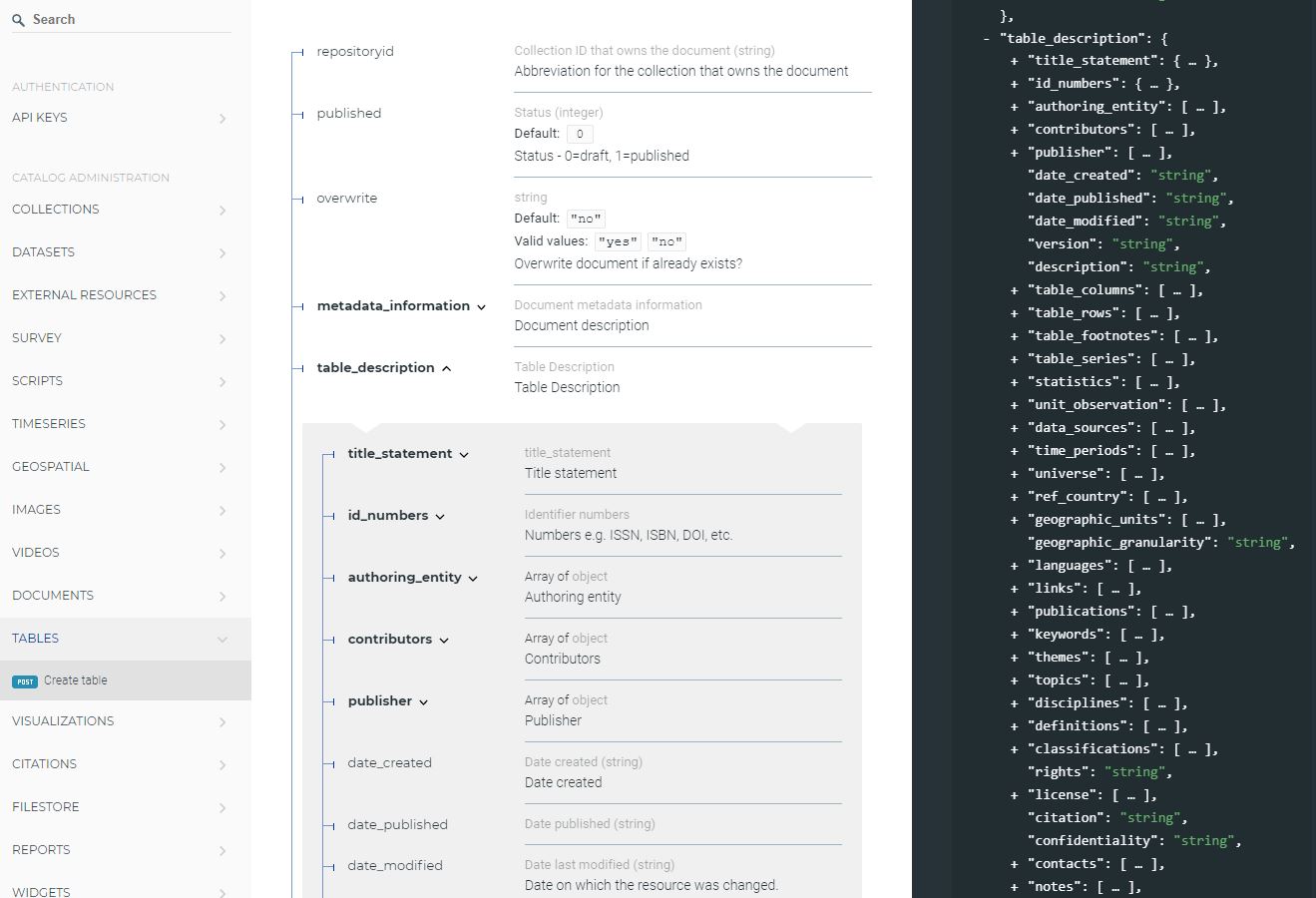
The documentation of each standard or schema starts with four common elements that are not actually part of the standard or schema, but that contain information that will be used when the metadata are published in a data catalog that uses the NADA application. If NADA is not used, these “administrative elements” can be ignored.

repositoryididentifies the collection in which the metadata will be published.access_policydetermines if and how the data files will be accessible from the catalog in which the metadata are published. This element only applies to the microdata and geographic metadata standards. It makes use of a controlled vocabulary with the following access policy options:direct: data can be downloaded without requiring them to be registered;open: same as “direct”, with an open data license attached to the dataset;public: public use files, which only require users to be registered in the catalog;licensed: access to data is restricted to registered users who receive authorization to use the data, after submitting a request;remote: data are made available by an external data repository;data_na: data are not accessible to the public (only metadata are published).
publisheddetermines the status of the metadata in the on-line catalog (with options 0 = draft and 1 = published). Published entries are visible to all visitors of the on-line catalog; unpublished (draft) entries will only be visible by the catalog administrators and reviewers.overwritedetermines whether the metadata already in the catalog for this entry can be overwritten (iwith options yes or no, ‘no’ being the default).
This set of administrative elements is followed by one or multiple sections that contain the elements specific to each standard/schema. For example, the DDI Codebook metadata standard, used to document microdata, contains the following main sections:
document description: a description of the metadata (who documented the dataset, when, etc.) Most schemas will contain such a section describing the metadata, useful mainly to data curators and catalog administrators. In other schemas, this section may be namedmetadata_description.study description: the description of the survey/census/study, not including the data files and data dictionary.file description: a list and description of data files associated to the study.variable description: the data dictionary (description of variables).
The schema-specific sections are followed by a few other metadata elements common to most schemas. These elements are used to provide additional information useful for cataloguing and discoverability purposes. They include tags (which allow catalog administrators to attach tags to datasets independently of their type, which can be used as filters in the catalog), and external resources.
Some schemas provide the possibility for data curators to add their own metadata elements in an additional section. The use of additional elements should be the exception, as metadata standards and schemas are designed to provide all elements needed to fully document a data resource.
In each standard and schema, metadata elements can have the following properties:
- Optional or required. When an element is declared as required (or mandatory), the metadata will be considered invalid if it contains no information in that element. To keep the schemas flexible, very few elements are set as required. Note that it is possible for a metadata element to be
requiredbut have all its components (for elements that have sub-elements) declared as optional. This will be the case when at least one (but any) of the sub-element must contain information. It is also possible for an element to be declared optional but have one or more of its sub-elements declaredmandatory(this means that the field is optional, but if it is used, some of its features MUST be provided.) - Repeatable or Not repeatable. For example, the element
nationin the DDI standard is Repeatable because a dataset can cover more than one country, while the elementtitleis Not repeatable because a study should be identified by a unique title. - Type. This indicates the format of the information contained in an element. It can be a string (text), a numeric value, a boolean variable (TRUE/FALSE), or an array.
Some schemas may recommend controlled vocabularies for some elements. For example, the ISO 19139 used to document geographic datasets recommends …
In most cases however, controlled vocabularies are not part of the metadata standard or schema. They will be selected and activated in templates and applications. …example…
3.7 Generating structured metadata
Metadata compliant with the standards and schemas described in this Guide can be generated in two different ways: programmatically using a programming language like R or Python, or by using a specialized metadata editor application. The first option provides a high degree of flexibility and efficiency. It offers multiple opportunities to automate part of the metadata generation process, and to exploit advanced machine learning solutions to enhance metadata. Also, metadata generated using R or Python can also be published in a NADA catalog using the NADA API and the R package NADAR or the Python library PyNADA. The programmatic option may thus be the preferred option for organizations that have strong expertise in R or Python. For other organizations, and for some types of data, the use of a specialized metadata editor may be a better option. Metadata editors are specialized software applications designed to offer a user-friendly alternative to the programmatic generation of metadata. We provide in this section a brief description of how structured metadata can be generated and published using respectively R, Python, and a metadata editor application.
3.7.1 Generating compliant metadata using a metadata editor
The easiest way to generate metadata compliant with the standards and schemas we describe in this Guide is to use a specialized Metadata Editor. A Metadata Editor provides a user-friendly and flexible interface to document data. Most metadata editors are specific to a certain standard. The IHSN / World Bank developed an open source multi-standard Metadata Editor.
This Metadata Editor contains all suggested standards. The full version of each standard is embedded in the application. But few users will ever make use of all elements contained in the standard. And some will want to customize the instructions, labels of the metadata elements, controlled vocabularies, and instructions to curators who will enter the metadata.
The Metadata Editor allows users to develop their own templates based on the full version of the standards. A template is a subset of the elements available in the standard/schema, where the elements can be renamed and other customization can be made (within limits, as the metadata generated must remain compliant with the standard independently of the template).
Template manager:

image

image
(describe / provide bettere example)
3.7.2 Generating compliant metadata using R
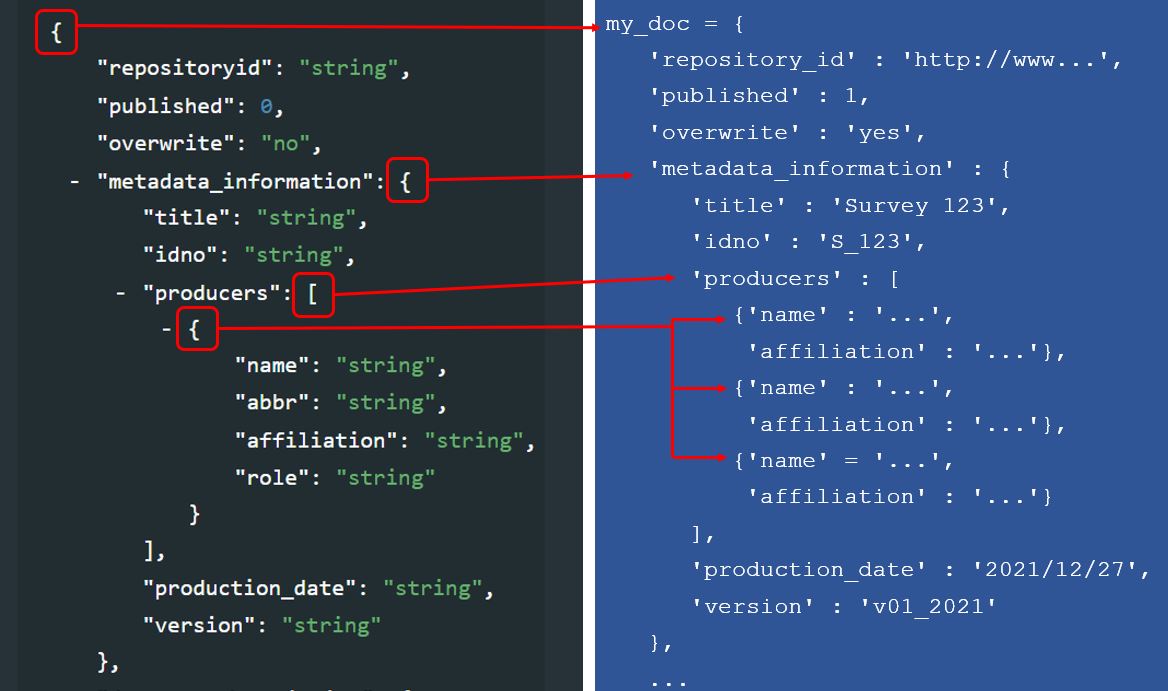
All schemas described in the on-line documentation can be used to generate compliant metadata using R scripts. Generating metadata using R will consist of producing a list object (itself containing lists). In the documentation of the standards and schemas, curly brackets indicate to R users that a list must be created to store the metadata elements. Square brackets indicate that a block of elements is repeatable, which corresponds in R to a list of lists. For example (using the DOCUMENT metadata schema):
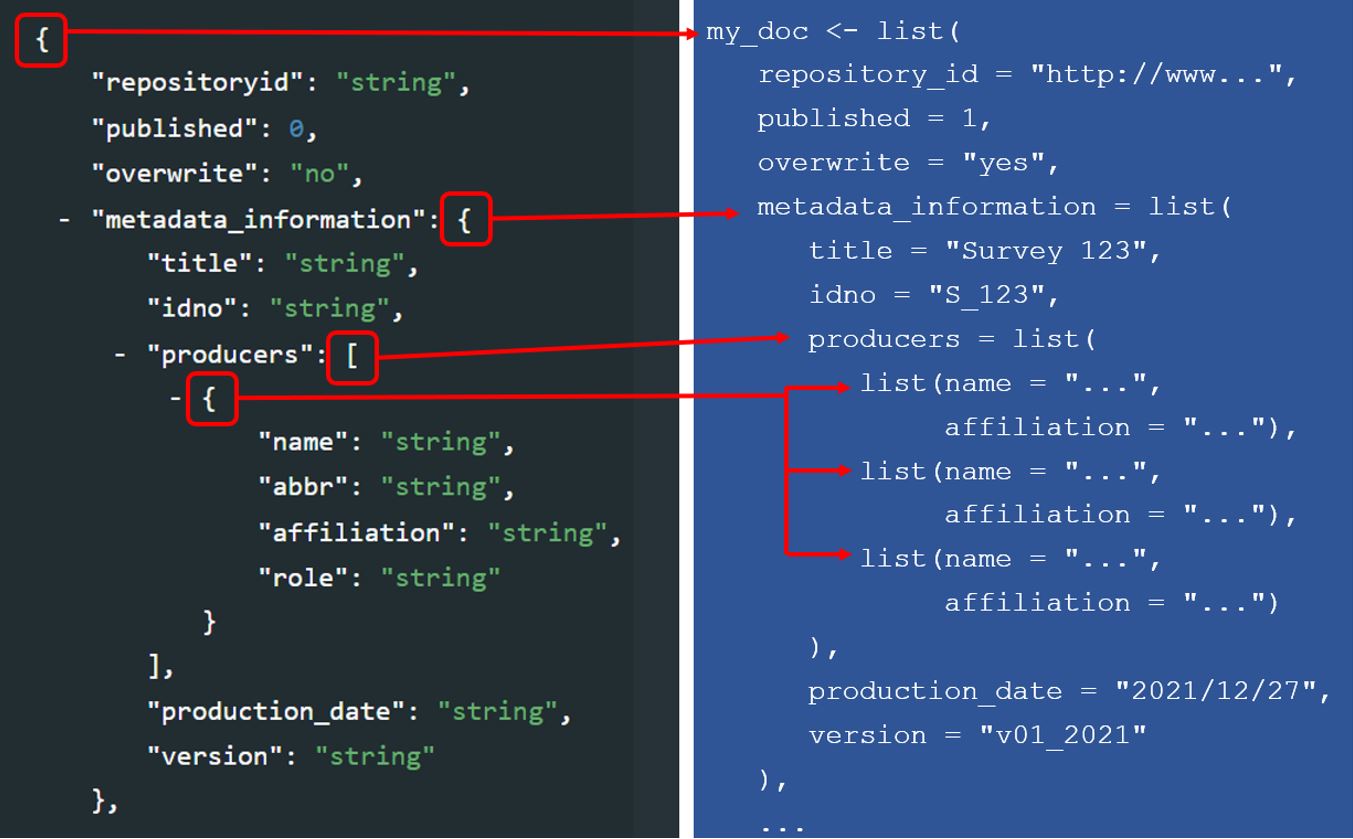
The sequence in which the metadata elements are created when documenting a dataset using R or Python does not have to match the sequence in the schema documentation.
Metadata compliant with a standard/schema can be generated using R, and directly uploaded in a NADA catalog without having to be saved as a JSON file. An object (a list) must be created in the R script that contains metadata compliant with the JSON schema. The example below shows how such an object is created and published in a NADA catalog. We assume here that we have a document with the following information:
- document unique id: WB_10986/7710
- title: Teaching in Lao PDR
- authors: Luis Benveniste, Jeffery Marshall, Lucrecia Santibañez (World Bank)
- date published: 2007
- countries: Lao PDR.
- The document is available from the World Bank Open knowledge Repository at http://hdl.handle.net/10986/7710.
We will use the DOCUMENT schema to document the publication, and the EXTERNAL RESOURCE schema to publish a link to the document in NADA.

Publishing data and metadata in a NADA catalog (using R and the NADAR package or Python and the PyNADA library) requires to first identify the on-line catalog where the metadata will be published (by providing its URL in the set_api_url command line) and to provide a key to authenticate as a catalog administrator (in the set_api_key command line; note that this key should never be entered in clear in a script to avoid accidental disclosure).
We then create an object (a list in R, or a dictionary in Python) that we will for example name my_doc. Within this list (or dictionary), we will enter all metadata elements. Some will be simple elements, others will be lists (or dictionaries). The first element to be included is the required document_description. Within it, we include the title_statement which is also required and contains the mandatory elements idno and title (all documents must have a unique ID number for cataloguing purpose, and a title). The list of countries that the document covers is a repeatable element, i.e. a list of lists (although we only have one country in this case). Information on the authors is a repeatable element, allowing us to capture the information on the three co-authors individually.
This my_doc object is then published in the NADA catalog using the add_document function. Last, we publish (as an external resource) a link to the file, with only basic information. We do not need to document this resource in detail, as it corresponds to the metadata provided in my_doc. If we had a different external resource (for example an MS-Excel table that contains all tables shown in the publication), we would make use of more of the external resources metadata elements to document it. Note that instead of a URL, we could have provided a path to an electronic file (e.g., to the PDF document), in which case the file would be uploaded to the web server and made available directly from the on-line catalog. We had previously captured a screenshot of the cover page of the document to be used as thumbnail in the catalog (optional).
library(nadar)
# Define the NADA catalog URL and provide an API key
set_api_url("http://nada-demo.ihsn.org/index.php/api/")
set_api_key("a1b2c3d4e5")
# Note: an administrator API key must always be kept strictly confidential;
# It is good practice to read it from an external file, not to enter it in clear
thumb <- "C:/DOCS/teaching_lao.JPG" # Cover page image to be used as thumbnail
# Generate and publish the metadata on the publication
doc_id <- "WB_10986/7710"
my_doc <- list(
document_description = list(
title_statement = list(
idno = doc_id,
title = "Teaching in Lao PDR"
),
date_published = "2007",
ref_country = list(
list(name = "Lao PDR", code = "LAO")
),
# Authors: we only have one author, but this is a list of lists
# as the 'authors' element is a repeatable element in the schema
authors = list(
list(first_name = "Luis", last_name = "Benveniste", affiliation = "World Bank"),
list(first_name = "Jeffery", last_name = "Marshall", affiliation = "World Bank"),
list(first_name = "Lucrecia", last_name = "Santibañez", affiliation = "World Bank")
)
)
)
# Publish the metadata in the central catalog
add_document(idno = doc_id,
metadata = my_doc,
repositoryid = "central",
published = 1,
thumbnail = thumb,
overwrite = "yes")
# Add a link as an external resource of type document/analytical (doc/anl).
external_resources_add(
title = "Teaching in Lao PDR",
idno = doc_id,
dctype = "doc/anl",
file_path = "http://hdl.handle.net/10986/7710",
overwrite = "yes"
)The document is now available in the NADA catalog.
3.7.3 Generating compliant metadata using Python
Generating metadata using Python will consist of producing a dictionary object, which will itself contain lists and dictionaries. Non-repeatable metadata elements will be stored as dictionaries, and repeatable elements as lists of dictionaries. In the metadata documentation, curly brackets indicate that a dictionary must be created to store the metadata elements. Square brackets indicate that a dictionary containing dictionaries must be created.
Dictionaries in Python are very similar to JSON schemas. When documenting a dataset, data curators who use Python can copy a schema from the ReDoc website, paste it in their script editor, then fill out the relevant metadata elements and delete the ones that are not used.
The Python equivalent of the R example we provided above is as follows:
import pynada as nada
# Define the NADA catalog URL and provide an API key
set_api_url("http://nada-demo.ihsn.org/index.php/api/")
set_api_key("a1b2c3d4e5")
# Note: an administrator API key must always be kept strictly confidential;
# It is good practice to read it from an external file, not to enter it in clear
thumb <- "C:/DOCS/teaching_lao.JPG" # Cover page image to be used as thumbnail
# Generate and publish the metadata on the publication
doc_id = "WB_10986/7710"
document_description = {
'title_statement': {
'idno': "WB_10986/7710",
'title': "Teaching in Lao PDR"
},
'date_published': "2007",
'ref_country': [
{'name': "Lao PDR", 'code': "Lao"}
],
# Authors: we only have one author, but this is a list of lists
# as the 'authors' element is a repeatable element in the schema
'authors': [
{'first_name': "Luis", 'last_name': "Benveniste", 'affiliation' = "World Bank"},
{'first_name': "Jeffery", 'last_name': "Marshall", 'affiliation' = "World Bank"},
{'first_name': "Lucrecia", 'last_name': "Santibañez", 'affiliation' = "World Bank"},
]
}
# Publish the metadata in the central catalog
nada.create_document_dataset(
dataset_id = doc_id,
repository_id = "central",
published = 1,
overwrite = "yes",
my_doc_metadata, @@@@@@
thumbnail_path = thumb)
# Add a link as an external resource of type document/analytical (doc/anl).
nada.add_resource(
dataset_id = doc_id,
dctype = "doc/anl",
title = "Teaching in Lao PDR",
file_path = "http://hdl.handle.net/10986/7710",
overwrite = "yes")[^1] See Omar Benjelloun, Shiyu Chen, Natasha Noy, 2020, Google Dataset Search by the Numbers, https://doi.org/10.48550/arXiv.2006.06894