Chapter 8 Indicators and time series
8.1 Indicators, time series, database, and scope of the schema
Indicators are summary measures related to key issues or phenomena, derived from observed facts. Indicators form time series when they are provided with a temporal ordering, i.e. when their values are provided with an ordered annual, quarterly, monthly, daily, or other time reference. Time series are usually published with equal intervals between values. In the context of this Guide, we however consider as time series all indicators provided for a given geographic area with an associated time reference, whether this time represents a regular, continuous succession of time stamps or not. For example, the indicators provided by the Demographic and Health Surveys (DHS) StatCompiler, which are only available for the years when DHS are conducted in countries (which for some countries can be a single year), would be considered here as “time series”.
Time series are often contained in multi-indicators databases, like the World Bank’s World Development Indicators - WDI, whose on-line version contains series for 1,430 indicators (as of 2021). To document not only the series but also the databases they belong to, we propose two metadata schemas: one to document the series/indicators, the other one to document the databases they belong to.
In the NADA application, a series can be documented and published without an associated database, but information on a database will only be published in association with a series. The information on a database is thus treated as an “attachment” to the information on a series. A SERIES DESCRIPTION tab will display all metadata related to the series, i.e. all content entered in the series schema.
 |
The (optional) SOURCE DATABASE tab will display the metadata related to the database, i.e. all content entered in the series database schema. This information is displayed for information, but not indexed in the NADA catalog (i.e. not searchable).
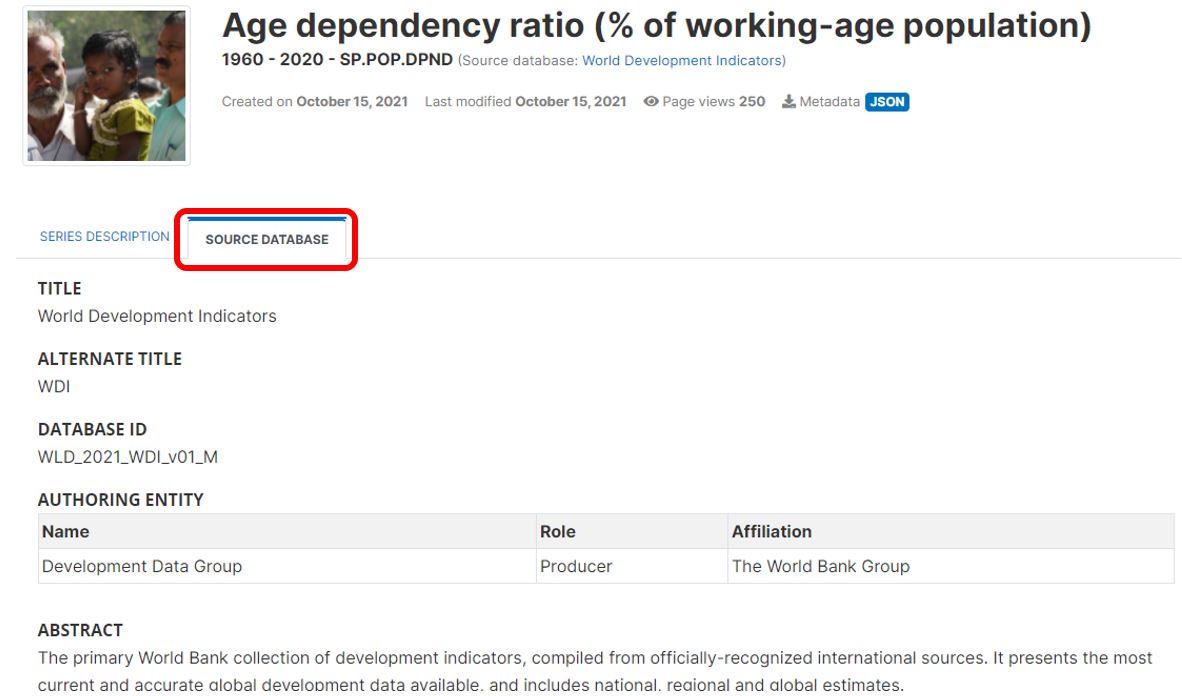 |
Suggestions and recommendations to data curators
Indicators and time series often come with metadata limited to the indicators/series name and a brief definition. This significantly reduces the discoverability of the indicators, and the possibility to implement semantic searchability and recommender systems. It is therefore highly recommended to generate more detailed metadata for each time series, including information on the purpose and typical use of the indicators, of its relevancy to different audiences, of its limitations, and more.
When documenting an indicator or time series, attention should be paid to include keywords and phrases in the metadata that reflect how data users are likely to formulate their queries when searching data catalogs. Subject-matter expertise, combined with an analysis of queries submitted to data catalogs, can help to identify such keywords. For example, the metadata related to an indicator “Prevalence of stunting” should contain the keyword “malnutrition”, and the metadata related to “GDP per capita” should include keywords like “economic growth” or “national income”. By doing so, data curators will provide richer input to search engines and recommender systems, and will have a significant and direct impact on the discoverability of the data. The use of AI tools can considerabli facilitate the process of identifying related keywords. We provide in the chapter an example of use of chatGPT for such purpose.
8.2 Schema description
An indicator or time series is documented using the time series /indicators schema. The database schema is optional, and used to document the database, if any, that the indicator belongs to. When multiple series of a same database are documented, the metadata related to the database only needs to be generated once, then applied to all series. One metadata element in the time series /indicators schema is used to link an indicator to the corresponding database.
8.2.1 The time series (indicators) schema
The time series schema is used to document an indicator or a time series. In NADA, the data and metadata of an indicator can (but does not have to) be published with information on the database it belongs to (if any). A metadata element is provided to indicate the identifier of that database (if any), and to establish the link between the indicator metadata and the database metadata generated using the schema described above.
{
"repositoryid": "string",
"access_policy": "na",
"data_remote_url": "string",
"published": 0,
"overwrite": "no",
"metadata_information": {},
"series_description": {},
"provenance": [],
"tags": [],
"lda_topics": [],
"embeddings": [],
"additional": { }
}8.2.1.1 Cataloguing parameters
The first elements of the schema (repositoryid, access_policy, data_remote_url, published, and overwrite) are not part of the series metadata. They are parameters used to indicate how the series will be published in a NADA catalog.
repositoryid identifies the collection in which the metadata will be published. By default, the metadata will be published in the central catalog. To publish them in a collection, the collection must have been previously created in NADA.
access_policy indicates the access policy to be applied to the data: direct access, open access, public use files, licensed access, data accessible from an external repository, and data not accessible. A controlled vocabulary is provided and must be used, with the following respective options: {direct; open; public; licensed; remote; data_na}.
data_remote_url provides the link to an external website where the data can be obtained, if the access_policy has been set to remote.
published: Indicates whether the metadata must be made visible to visitors of the catalog. By default, the value is 0 (unpublished). This value must be set to 1 (published) to make the metadata visible.
overwrite: Indicates whether metadata that may have been previously uploaded for the same series can be overwritten. By default, the value is “no”. It must be set to “yes” to overwrite existing information. Note that a series will be considered as being the same as a previously uploaded one if the identifier provided in the metadata element series_description > idno is the same.
8.2.1.2 Metadata information
metadata_information [Optional, Not Repeatable]
The set of elements in metadata_information is used to provide information on the production of the indicator metadata. This information is used mostly for administrative purposes by data curators and catalog administrators.
"metadata_information": {
"title": "string",
"idno": "string",
"producers": [
{
"name": "string",
"abbr": "string",
"affiliation": "string",
"role": "string"
}
],
"prod_date": "string",
"version": "string"
}title[Optional ; Not repeatable ; String]
The title of the metadata document containing the indicator metadata.idno[Required ; Not repeatable ; String]
A unique identifier of the indicator metadata document. It can be for example the identifier of the indicator preceded by a prefix identifying the metadata producer.producers[Optional ; Repeatable]
This is a list of producers involved in the documentation (production of the metadata) of the series.name[Optional ; Not repeatable, String]
The name of the agency that is responsible for the documentation of the series.abbr[Optional ; Not repeatable, String]
Abbreviation (acronym) of the agency mentioned inname.affiliation[Optional ; Not repeatable, String]
Affiliation of the agency mentioned inname.role[Optional ; Not repeatable, String]
The specific role of the agency mentioned innamein the production of the metadata. This element will be used when more than one person or organization is listed in theproducerselement to distinguish the specific contribution of each metadata producer.
prod_date[Optional ; Not repeatable, String]
The date the metadata was generated. The date should be entered in ISO 8601 format (YYYY-MM-DD or YYYY-MM or YYYY).version[Optional ; Not repeatable, String]
The version of the metadata on this series. This element will rarely be used.metadata_creation = list( producers = list(list(name = "Development Data Group", abbr = "DECDG", affiliation = "World Bank")), prod_date = "2021-10-15" )
8.2.1.3 Series description
series_description [Required ; Repeatable]
This section contains all elements used to describe a specific series or indicator.
"series_description": {
"idno": "string",
"doi": "string",
"name": "string",
"database_id": "string",
"aliases": [],
"alternate_identifiers": [],
"languages": [],
"measurement_unit": "string",
"dimensions": [],
"periodicity": "string",
"base_period": "string",
"definition_short": "string",
"definition_long": "string",
"definition_references": [],
"statistical_concept": "string",
"concepts": [],
"methodology": "string",
"derivation": "string",
"imputation": "string",
"missing": "string",
"quality_checks": "string",
"quality_note": "string",
"sources_discrepancies": "string",
"series_break": "string",
"limitation": "string",
"themes": [],
"topics": [],
"disciplines": [],
"relevance": "string",
"time_periods": [],
"ref_country": [],
"geographic_units": [],
"bbox": [],
"aggregation_method": "string",
"disaggregation": "string",
"license": [],
"confidentiality": "string",
"confidentiality_status": "string",
"confidentiality_note": "string",
"links": [],
"api_documentation": [],
"authoring_entity": [],
"sources": [],
"sources_note": "string",
"keywords": [],
"acronyms": [],
"errata": [],
"notes": [],
"related_indicators": [],
"compliance": [],
"framework": [],
"series_groups": []
}idno[Required ; Not repeatable ; String]A unique identifier (ID) for the series. Most agencies and databases will have a coherent coding convention to generate their series IDs. For example, the name of the series in the World Bank’s World Development Indicators series are composed of the following elements, separated by a dot:
- Topic code (2 digits).
- General subject code (3 digits)
- Specific subject code (4 digits)
- Extensions (2 digits each)
For example, the series with identifier “DT.DIS.PRVT.CD” is the series containing data on “External debt disbursements by private creditors in current US dollars” (for more information, see How does the World Bank code its indicators?.
doi[Optional ; Not repeatable ; String]A Digital Object Identifier (DOI) for the the series.
name[Required ; Not repeatable ; String]The name (label) of the series. Note that a field
aliasis provided (see below) to capture alternative names for the series.database_id[Optional ; Not repeatable ; String]The unique identifier of the database the series belongs to. This field must correspond to the element
database_description > title_statement > idnoof the database schema described above. This is the only field that is needed to establish the link between the database metadata and the indicator metadata.aliases[Optional ; Repeatable]
A series or an indicator can be referred to using different names. Thealiaseselement is provided to capture the multiple names and labels that may be associated with (i.e synomyms of) the documented series or indicator.
"aliases": [
{
"alias": "string"
}
]
- alias [Optional ; Not repeatable ; String]
An alternative name for the indicator or series being documented.
alternate_identifiers[Optional ; Not repeatable ; String]
The elementidnodescribed above is the reference unique identifier for the catalog in which the metadata is intended to be published. But the same indicator/metadata may be published in other catalogs. For example, a data catalog may publish metadata for series extracted from the World Bank World Development Indicators (WDI) database. And the WDI itself contains series generated and published by other organizations, such as the World Health Organization or UNICEF. Catalog administrators may want to assign a unique identifier specific to their catalog (theidnoelement), but keep track of the identifier of the series or indicator in other catalogs or databases. Thealternate_identifierselement serves that purpose.
"alternate_identifiers": [
{
"identifier": "string",
"name": "string",
"database": "string",
"uri": "string",
"notes": "string"
}
]identifier[Required ; Not repeatable ; String]
An identifier for the series other than the identifier entered inidno(note that the identifier entered inidnocan be included in this list, if it is useful to provide it with a type identifier (seenameelement below) which is not provided inidno. This can be the identifier of the indicator in another database/catalog, or a global unique identifier.name
This element will be used to define the type of identifier. This will typically be used to flag DOIs by entering “Digital Object Identifier (DOI)”.database
The name of the database (or catalog) where this alternative identifier is used, e.g. “IMF, International Financial Statistics (IFS)”.uri[Optional ; Not repeatable ; String]
A link (URL) to the database mentioned indatabase.notes[Optional ; Not repeatable ; String]
Any additional information on the alternate identifier.languages[Optional ; Repeatable]
An indicator or time series can be made available at different levels of disaggregation. For example, an indicator containing estimates of the “Population” of a country by year can be available by sex. The data curators in such case will have two options: (i) create and document three separate indicators, namely “Population, Total”, “Population, Female”, and “Population, Male”; or create a single indicator “Population” and attach a dimension “sex” to it, with values “Total”, “Female”, and “Male”. Thedimensionsare features (or “variables”) that define the different levels of disaggregation within an indicator/series. The elementdimensionsis used to provide an itemized list of disaggregations that correspond exactly to the published data. Note that when an indicator is available at two “non-overlapping” levels of disaggregation, it should be split into two indicators. For example, if the Population indicator is available by male/female and by urban/rural, but not by male/urban/male/rural/female urban/female rural, it should be treated as two separate indicators (“Population by sex” with dimension sex = “male / female” and “Population by area of residence” with dimension area = “urban / rural”.) Note also that another element in the schema,disaggregation, is also provided, in which a narrative description of the actual or recommended disaggregations can be documented.
"alternate_identifiers": [
{
"identifier": "string",
"name": "string",
"database": "string",
"uri": "string",
"notes": "string"
}
]name[Required ; Not repeatable ; String]
The name of the language.code[Optional ; Not repeatable ; String]
The code of the language, preferably the ISO code.measurement_unit[Optional ; Not repeatable ; String]The unit of measurement. Note that in many databases the measurement unit will be included in the series name/label. In the World Bank’s World Development Indicators for example, series are named as follows:
- CO2 emissions (kg per 2010 US$ of GDP)
- GDP per capita (current US$)
- GDP per capita (current LCU)
- Population density (people per sq. km of land area)
In such case, the name of the series should not be changed, but the measurement unit may be extracted from it and stored in element
measurement_unit.dimensions[Optional ; Repeatable]
An indicator or time series can be made available at different levels of disaggregation. For example, a time series containing annual estimates of the indicator “Resident population (mid-year)” can be provided by country, by urban/rural area of residence, by sex, by age group. The data curator has to make a decision on how to organize such data. One option is to create an indicator “Resident population (mid-year)” and to define a set of “dimensions” for the breakdowns. The dimensions would in such case be the year, the country, the area of residence, the sex, and the age group. Some of the dimensions would have to be provided with a code list (or ’controlled vocabulary”, for example stating that F means “Female”, M” means male, and T means “Total” for the dimension sex). Another option would be to create multiple indicators (e.g., creating three distinct indicators “Resident population, male (mid-year)”, “Resident population, female (mid-year)”, “Resident population, total (mid-year)” and using year, country, area of residence, and age group as dimensions). The elementdimensionsis used to provide an itemized list of disaggregations that correspond to the published data. Note that another element in the schema,disaggregation, is also provided, in which a narrative description of the actual or recommended disaggregations can be documented. Note also that in the SDMX standard, dimensions are listed in the Data Structure Definition” and are complemented by code lists* that provide the related controlled vocabularies.
"dimensions": [
{
"name": "string",
"label": "string",
"description": "string"
}
]name[Required ; Not repeatable ; String]
The name of the dimension.label[Required ; Not repeatable ; String]
The label of the dimension, for example “sex”, or “urban/rural”.description[Optional ; Not repeatable ; String]
A description of the dimension (for example, if the label was “age group”, the description can provide detailed information on the age groups, e.g. “The age groups in the database are 0-14, 15-49, 50-64, and 65+ years old”.)release_calendar[Optional ; Not repeatable ; String]Information on when updates for the indicators can be expected. This will usually not consist of exact dates (which would have to be updated regularly), but of more general information like “Every first Monday of the Month”, or “Every year on June 30”, or “The last week of each quarter”.
periodicity[Optional ; Not repeatable ; String]The periodicity of the series. It is recommended to use a controlled vocabulary with values like annual, quarterly, monthly, daily, etc.
base_period[Optional ; Not repeatable ; String]The base period for the series. This field will only apply to series that require a base year (or other reference time) used as a benchmark, like a Consumer Price Index (CPI) which will have a value of 100 for a reference base year.
definition_short[Optional ; Not repeatable ; String]
A short definition of the series. The short definition captures the essence of the series.definition_long[Optional ; Not repeatable ; String]
A long(er) version of the definition of the series. If only one definition is available (not a short/long version), it is recommended to capture it in thedefinition_shortelement. ALternatively, the same definition can be stored in bothdefinition_shortanddefinition_long.definition_references[Optional ; Repeatable]
This element is provided to link to an external resources from which the definition was extracted.
"definition_references": [
{
"source": "string",
"uri": "string",
"note": "string"
}
]source[Optional ; Not repeatable ; String]
The source of the definition (title, or label).uri[Optional ; Not repeatable ; String]
A link (URL) to the source of the definition.note[Optional ; Not repeatable ; String]
This element provides for annotating or explaining the reason the reference has been included as part of the metadata.statistical_concept[Optional ; Not repeatable ; String]This element allows to insert a reference of the series with content of a statistical character. This can include coding concepts or standards that are applied to render the data statistically relevant.
concepts[Optional ; Repeatable]
This repeatable element can be used to document concepts related to the indicators or time series (other than the main statistical concept that may have been entered instatisticsl_concept). For example, the concept of malnutrition could be documented in relation to the indicators “Prevalence of stunting” and “Prevalence of wasting”.
"concepts": [
{
"name": "string",
"definition": "string",
"uri": "string"
}
]name[Required ; Not repeatable ; String]
A concise and standardized name (label) for the concept.definition[Required ; Not repeatable ; String]
The definition of the concept.uri[Optional ; Not repeatable ; String]
A link (URL) to a resource providing more detailed information on the concept.data_collection[Optional ; Not repeatable]
This group of elements can be used to document data collection activities that led to or allowed the production of the indicator. This element will typically be used for the description of surveys or censuses. Note: the schema also contains an element “sources”. That element will be used to document the organization and/or main data production program from which the indicator is derived.
"data_collection": [
{
"data_source": "string",
"method": "string",
"period": "string",
"note": "string"
"uri": "string"
}
]data_source[Required ; Not repeatable ; String]
A concise and standardized name (label) for the data source, e.g. “National Labor Force Survey, 1st quarter 2022”. If multiple data sources were used, they can all be listed here. Note that is a time series has values obtained from many different sources, the source for each value (or group of values) will not be part of the indicator/series metadata, but will be stored as an attribute in the data file where the information can be associated with a specific observation (“cell note” or group of observation (e.g. attached to an indicator for avv values for a same year or for a same area).method[Required ; Not repeatable ; String]
Brief information on the data collection method, e.g. :Sample household survey”.period[Optional ; Not repeatable ; String]
Information on the period of the data collection, e.g. “January to March 2022”.note[Optional ; Not repeatable ; String]
Additional information on the data collection.uri[Optional ; Not repeatable ; String]
A link to a resource (website, document) where more information on the data collection can be found.imputation[Optional ; Not repeatable ; String]Data may have been imputed to account for data gaps or for other reasons (harmonization/standardization, and others). If imputations have been made, this element provides the space for their description.
adjustments[Optional ; Repeatable ; String]Description of any adjustments with respect to use of standard classifications and harmonization of breakdowns for age group and other dimensions, or adjustments made for compliance with specific international or national definitions.
missing[Optional ; Not repeatable ; String]Information on missing values in the series or indicator. This information can be related to treatment of missing values, to the cause(s) of missing values, and others.
validation_rules[Optional ; Repeatable ; String]Description of the set of rules (itemized) used to validate values for the indicator, e.g. “Is within range 0-100”, or “Is the sum of indicatorX + indicator Y”.
quality_checks[Optional ; Not repeatable ; String]Data may have gone through data quality checks to assure that the values are reasonable and coherent, which can be described in this element. These quality checks may include checking for outlying values or other. A brief description of such quality control procedures will contribute to reinforcing the credibility of the data being disseminated.
quality_note[Optional ; Not repeatable ; String]Additional notes or an overall statement on data quality. These could for example cover non-standard quality notes and/or information on independent reviews on the data quality.
sources_discrepancies[Optional ; Not repeatable ; String]This element is used to describe and explain why the data in the series may be different from the data for the same series published in other sources. International organizations, for example, may apply different techniques to make data obtained from national sources comparable across countries, in which cases the data published in international databases may differ from the data published in national, official databases.
series_break[Optional ; Not repeatable ; String]Breaks in statistical series occur when there is a change in the standards, sources of data, or reference year used in the compilation of a series. Breaks in series must be well documented. The documentation should include the reason(s) for the break, the time it occured, and information on the impact on comparability of data over time.
limitation[Optional ; Not repeatable ; String]This element is used to communicate to the user any limitations or exceptions in using the data. The limitations may result from the methodology, from issues of quality or consistency in the data source, or other.
themes[Optional ; Repeatable]
Themes provide a general idea of the research that might guide the creation and/or demand for the series. A theme is broad and is likely also subject to a community based definition or list. A controlled vocabulary should be used. This element will rarely be used (the elementtopicsdescribed below will be used more often).
"themes": [
{
"id": "string",
"name": "string",
"parent_id": "string",
"vocabulary": "string",
"uri": "string"
}
]id[Optional ; Not repeatable ; String]
The unique identifier of the theme. It can be a sequential number, or the ID of the theme in a controlled vocabulary.name[Required ; Not repeatable ; String]
The label of the theme associated with the data.parent_id[Optional ; Not repeatable ; String]
When a hierarchical (nested) controlled vocabulary is used, theparent_idfield can be used to indicate a higher-level theme to which this theme belongs.vocabulary[Optional ; Not repeatable ; String]
The name of the controlled vocabulary used, if any.uri[Optional ; Not repeatable ; String]
A link to the controlled vocabulary mentioned in field `vocabulary’.topics[Optional ; Repeatable]
Thetopicsfield indicates the broad substantive topic(s) that the indicator/series covers. A topic classification facilitates referencing and searches in electronic survey catalogs. Topics should be selected from a standard controlled vocabulary such as the Council of European Social Science Data Archives (CESSDA) topics classification.
"topics": [
{
"id": "string",
"name": "string",
"parent_id": "string",
"vocabulary": "string",
"uri": "string"
}
]id[Optional ; Not repeatable ; String]
The unique identifier of the topic. It can be a sequential number, or the ID of the topic in a controlled vocabulary.name[Required ; Not repeatable ; String]
The label of the topic associated with the data.
parent_id[Optional ; Not repeatable ; String]
When a hierarchical (nested) controlled vocabulary is used, theparent_idfield can be used to indicate a higher-level topic to which this topic belongs.vocabulary[Optional ; Not repeatable ; String]
The name of the controlled vocabulary used, if any.uri
A link to the controlled vocabulary mentioned in fieldvocabulary.disciplines[Optional ; Repeatable]
Information on the academic disciplines related to the content of the document. A controlled vocabulary will preferably be used, for example the one provided by the list of academic fields in Wikipedia.
"disciplines": [
{
"id": "string",
"name": "string",
"parent_id": "string",
"vocabulary": "string",
"uri": "string"
}
]This is a block of five elements:
id[Optional ; Not repeatable ; String]
The ID of the discipline, preferably taken from a controlled vocabulary.name[Optional ; Not repeatable ; String]
The name (label) of the discipline, preferably taken from a controlled vocabulary.parent_id[Optional ; Not repeatable ; String]
The parent ID of the discipline (ID of the item one level up in the hierarchy), if a hierarchical controlled vocabulary is used.vocabulary[Optional ; Not repeatable ; String]
The name (including version number) of the controlled vocabulary used, if any.uri[Optional ; Not repeatable ; String]
The URL to the controlled vocabulary used, if any.relevance[Optional ; Not repeatable ; String]This field documents the relevance of an indicator or series in relation to a social imperative or policy objective.
mandate[Optional ; Not repeatable ; String]mandate[Optional ; Not repeatable ; String]
Description of the institutional mandate or of a set of rules or other formal set of instructions assigning responsibility as well as the authority to an organization for the collection, processing, and dissemination of statistics for this indicator.URI[Optional ; Not repeatable ; String]
A link to a resource (document, website) describing the mandate.
time_periods[Optional ; Repeatable]
The time period covers the entire span of data available for the series. The time period has a start and an end and is reported according to the periodicity provided in a previous element.
"time_periods": [
{
"start": "string",
"end": "string",
"notes": "string"
}
]start[Required ; Not repeatable ; String]
The initial date of the series in the dataset. The start date should be entered in ISO 8601 format (YYYY-MM-DD or YYYY-MM or YYYY).end[Required ; Not repeatable ; String]
The end date is the latest date for which an estimate for the indicator is available. The end date should be entered in ISO 8601 format (YYYY-MM-DD or YYYY-MM or YYYY).notes[Optional ; Not repeatable ; String]
Additional information on the time period.ref_country[Optional ; Repeatable]
A list of countries for which data are available in the series. This element is somewhat redundant with the next element (geographic_units) which may also contain a list of countries. Identifying geographic areas of type “country” is important to enable filters and facets in data catalogs (country names are among the most frequent queries submitted to catalogs).
"ref_country": [
{
"name": "string",
"code": "string"
}
]name[Required ; Not repeatable ; String]
The name of the country.code[Optional ; Not repeatable ; String]
The code of the country. The use of the ISO 3166-1 alpha-3 codes is recommended.geographic_units[Optional ; Repeatable]
List of geographic units (regions, countries, states, provinces, etc.) for which data are available for the series.
"geographic_units": [
{
"name": "string",
"code": "string",
"type": "string"
}
]name[Required ; Not repeatable ; String]
Name of the geographic unit e.g. “World,”Africa”, “Afghanistan”, “OECD countries”, “Bangkok”.code[Optional ; Not repeatable ; String]
Code of the geographic unit. The ISO 3166-1 alpha-3 code is preferred when the unit is a country.type[Optional ; Not repeatable ; String]
Type of geographic unit e.g. “country”, “state”, “region”, “province”, “city”, etc.bbox[Optional ; Repeatable]
This element is used to define one or multiple bounding box(es), which are the rectangular fundamental geometric description of the geographic coverage of the data. A bounding box is defined by west and east longitudes and north and south latitudes, and includes the largest geographic extent of the dataset’s geographic coverage. The bounding box provides the geographic coordinates of the top left (north/west) and bottom-right (south/east) corners of a rectangular area. This element can be used in catalogs as the first pass of a coordinate-based search. This element is optional, but if thebound_polyelement (see below) is used, then thebboxelement must be included.
"bbox": [
{
"west": "string",
"east": "string",
"south": "string",
"north": "string"
}
]west[Required ; Not repeatable ; String]
West longitude of the bounding box.east[Required ; Not repeatable ; String]
East longitude of the bounding box.south[Required ; Not repeatable ; String]
South latitude of the bounding box.north[Required ; Not repeatable ; String]
North latitude of the bounding box.
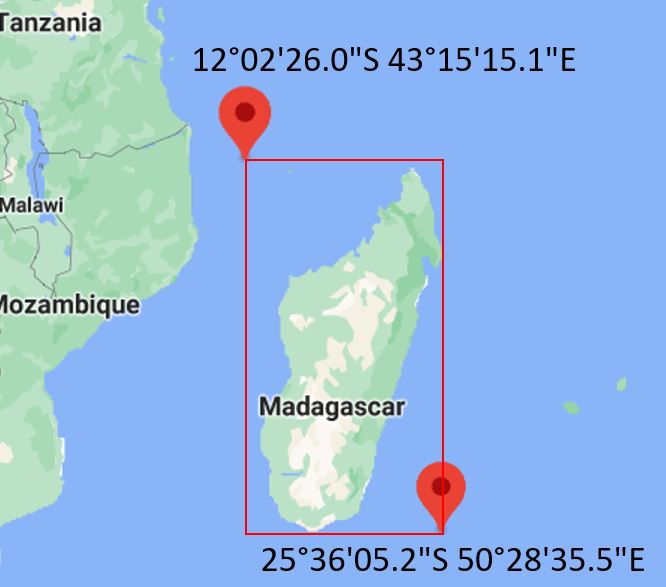
my_indicator <- list(
metadata_information = list(
# ...
),
series_description = list(
# ... ,
study_info = list(
# ... ,
ref_country = list(
list(name = "Madagascar", code = "MDG"),
list(name = "Mauritius", code = "MUS")
),
bbox = list(
list(name = "Madagascar",
west = "43.2541870461",
east = "50.4765368996",
south = "-25.6014344215",
north = "-12.0405567359"),
list(name = "Mauritius",
west = "56.6",
east = "72.466667",
south = "-20.516667",
north = "-5.25")
),
# ...
),
# ...
) aggregation_method[Optional ; Not repeatable ; String]The
aggregation_methodelement describes how values can be aggregated from one geographic level (for example, a country) to a higher-level geographic area (for example, a group of country defined based on a geographic criteria (region, world) or another criteria (low/medium/high-income countries, island countries, OECD countries, etc.). The aggregation method can be simple (like “sum” or “population-weighted average”) or more complex, involving weighting of values.disaggregation[Optional ; Not repeatable ; String]This element is intended to inform users that an indicator or series is available at various levels of disaggregation. The related series should be listed (by andme and/or identifier). For indicator “Population, total” for example, one may inform the user that the indicator is also available (in other series) by sex, urban/rural, and age group (in series “Population, male” and “Population, female”, etc.).
license[Optional ; Repeatable]
The license refers to the accessibility and terms of use associated with the data. Providing a license and a link to the terms of the license allos data users to determine, with full clarity, what they can and cannot do with the data.
"license": [
{
"name": "string",
"uri": "string",
"note": "string"
}
]name[Required ; Not repeatable ; String]
The name of the license, e.g. “Creative Commons Attribution 4.0 International license (CC-BY 4.0)”.uri[Optional ; Not repeatable ; String]
The URL of a website where the licensed is described in detail, for example “https://creativecommons.org/licenses/by/4.0/”.note[Optional ; Not repeatable ; String]
Any additional information on the license.confidentiality[Optional ; Not repeatable ; String]A statement of confidentiality for the series.
confidentiality_status[Optional ; Not repeatable ; String]This indicates a confidentiality status for the series. A controlled vocabulary should be used with possible options “public”, “official use only”, “confidential”, “strictly confidential”. When all series are made publicly available, and belong to a database that has an open or public access policy, this element can be ignored.
confidentiality_note[Optional ; Not repeatable ; String]This element is reserved for additional notes regarding confidentiality of the data. This could involve references to specific laws and circumstances regarding the use of data.
links[Optional ; Repeatable]
This element provides links to online resources of any type that could be useful to the data users. This can be links to description of methods and reference documents, analytics tools, visualizations, data sources, or other.
"links": [
{
"type": "string",
"description": "string",
"uri": "string"
}
]type[Optional ; Not repeatable ; String]
This element allows to classify the link that is provided.description[Optional ; Not repeatable ; String]
A description of the link that is provided.uri[Optional ; Not repeatable ; String]
The uri (URL) to the described resource.api_documentation[Optional ; Repeatable]
Increasingly, data are made accessible via Application Programming Interfaces (APIs). The API associated with a series must be documented. The documentation will usually not be specific to a series, but apply to all series in a same database.
"api_documentation": [
{
"description": "string",
"uri": "string"
}
]description[Optional ; Not repeatable ; String]
This element will not contain the API documentation itself, but information on what documentation is available.uri[Optional ; Not repeatable ; String]
The URL of the API documentation.authoring_entity[Optional ; Repeatable]
This set of five elements is used to identify the organization(s) or person(s) who are the main producers/curators of the indicator. Note that a similar element is provided at the database level. The authoring_entity for the indicator can be different from the authoring_entity of the database. For example, the World Bank is the authoring entity for the World Development Indicators database, which contains indicators obtained from the International Monetary Fund, World Health Organization, and other organizations that are thus the authoring entitis for specific indicators.
"authoring_entity": [
{
"name": "string",
"affiliation": "string",
"abbreviation": null,
"email": null,
"uri": "string"
}
]name[Optional ; Not repeatable ; String]
The name of the person or organization who is responsible for the production of the indicator or series. Write the name in full (use the elementabbreviationto capture the acronym of the organization, if relevant).affiliation[Optional ; Not repeatable ; String]
The affiliation of the person or organization mentioned inname.
abbreviation[Optional ; Not repeatable ; String]
Abbreviated name (acronym) of the organization mentioned inname.email[Optional ; Not repeatable ; String]
The public email contact of the person or organizations mentioned inname. It is good practice to provide a service account email address, not a personal one.uri[Optional ; Not repeatable ; String]
A link (URL) to the website of the entity mentioned inname.sources[Optional ; Not repeatable ; String]
This element provides information on the source(s) of data that were used to generate the indicator. A source can refer to an organization (e.g., “Source: World Health Organization”), or to a dataset (e.g., for a national poverty headcount indicator, the sources will likely be a list of sample household surveys). Insources, we are mainly interested in the latter. When a series in a database is a series extracted from another database (e.g., when the World Bank World Development Indicators include a series from the World Health Organization in its database), the source organization should be mentioned in theauthoring_entityelement of the schema. Thesourceselement is a repeatable element. Note 1: In some cases, the source of a specific value in a database will be stored as an attribute of the data file (e.g., as a “footnote” attached to a specific cell. If the sources are listed in the data file, they may but do not need to be stored in the metadata. Note 2: the schema also contains an element “data_collection” that would be used to describe a specific data collection activity from which an indicator is derived.
"sources": [
{
"id": "string",
"name": "string",
"organization": "string",
"type": "string",
"note": "string"
}
]id[Required ; String]
This element records the unique identifier of a source. It is a required element. If the source does not have a specific unique identifier, a sequential number can be used. If the source is a dataset or database that has its own unique identifier (possibly a DOI), this identifier should be used.name[Optional ; String]
The name (title, or label) of the source.organization[Optional ; String]
The organization responsible for the source data.
type[Optional ; String]
The type of source, e.g. “household survey”, “administrative data”, or “external database”.
note[Optional ; String]
This element can be used to provide additional information regarding the source data.sources_note[Optional ; Not repeatable ; String]Additional information on the source(s) of data used to generate the series or indicator.
keywords[Optional ; Repeatable]
Words or phrases that describe salient aspects of a data collection’s content. Can be used for building keyword indexes and for classification and retrieval purposes. A controlled vocabulary can be employed. Keywords should be selected from a standard thesaurus, preferably an international, multilingual thesaurus.
"keywords": [
{
"name": "string",
"vocabulary": "string",
"uri": "string"
}
]name[Required ; String ; Non repeatable]
Keyword (or phrase). Keywords summarize the content or subject matter of the study.vocabulary[Optional ; Not repeatable ; String]
Controlled vocabulary from which the keyword is extracted, if any.
uri[Optional ; Not repeatable ; String]
The URI of the controlled vocabulary used, if any.acronyms[Optional ; Repeatable]
Theacronymselement is used to document the meaning of all acronyms used in the metadata of a series. If some acronyms are well known (like “GDP”, or “IMF” for example), others may be less obvious or could be uncertain (does “PPP” mean “public-private partnership”, or “purchasing power parity”?). In any case, providing a list of acronyms with their meaning will help users and make your metadata more discoverable. Note that acronyms should not include country codes used in the documentation of the geographic coverage of the data.
"acronyms": [
{
"acronym": "string",
"expansion": "string",
"occurrence": 0
}
]acronym[Required ; Not repeatable ; String]
An acronym referenced in the series metadata (e.g. “GDP”).expansion[Required ; Not repeatable ; String]
The expansion of the acronym, i.e. the full name or title that it represents (e.g., “Gross Domestic Product”).occurrence[Optional ; Not repeatable ; Numeric]
This numeric element can be used to indicate the number of times the acronym is mentioned in the metadata. The element will rarely be used.errata[Optional ; Repeatable]
This element is used to provide information on detected errors in the data or metadata for the series, and on the measures taken to remedy them.
"errata": [
{
"date": "string",
"description": "string"
}
]date[Required ; Repeatable ; String]
The date the erratum was published.description[Required ; Repeatable ; String]
A description of the error and remedy measures.notes[Optional ; Repeatable]
This element is open and reserved for explanatory notes deemed useful to the users of the data. Notes should account for additional information that might help: replicate the series; access the data and research area, or discoverability in general.
"notes": [
{
"note": "string"
}
]note[Required ; Repeatable ; String]
The note itself.related_indicators[Optional ; Repeatable]
This element allows to reference indicators that are often associated with the indicator being documented.
"related_indicators": [
{
"code": "string",
"label": "string",
"uri": "string"
}
]code[Optional ; Not repeatable ; String]
The code for the indicator that is referenced in the document. It will likely be an ID that is used by that indicator.label[Optional ; Not repeatable ; String]
The name or label of the indicator that is associated with the indicator being documented.uri[Optional ; Not repeatable ; String]
A link to the related indicator.compliance[Optional ; Repeatable]
For some indicators, international standards have been established. This is for example the case of indicators like the unemployment or unemployment rate, for which the International Conference of Labour Statisticians defines the standards concepts and methods. Thecomplianceelement is used to document the compliance of a series with one or multiple national or international standards.
"compliance": [
{
"standard": "string",
"abbreviation": "string",
"custodian": "string",
"uri": "string"
}
]standard[Optional ; Not repeatable ; String]
The name of the standard that the series complies with. This name will ideally include a label and a version or a date. For example: “International Standard Industrial Classification of All Economic Activities (ISIC) Revision 4, published in 2007”abbreviation[Optional ; Not repeatable ; String]
The acronym of the standard that the series complies with.custodian[Optional ; Not repeatable ; String]
The organization that maintains the standard that is being used for compliance. For example: “United Nations Statistics Division”.uri[Optional ; Not repeatable ; String]
A link to a public website site where information on the compliance standard can be obtained. For example: “https://unstats.un.org/unsd/classifications/Family/Detail/27framework[Optional ; Repeatable]
Some national, regional, and international agencies develop monitoring frameworks, with goals, targets, and indicators. Some well-known examples are the Millennium Development Goals and the Sustainable Development Goals which establish international goals for human development, or the World Summit for Children (1990) which set international goals in the areas of child survival, development and protection, supporting sector goals such as women’s health and education, nutrition, child health, water and sanitation, basic education, and children in difficult circumstances. Theframeworkelement is used to link an indicator or series to the framework, goal, and target associated with it.
"framework": [
{
"name": "string",
"abbreviation": "string",
"custodian": "string",
"description": "string",
"goal_id": "string",
"goal_name": "string",
"goal_description": "string",
"target_id": "string",
"target_name": "string",
"target_description": "string",
"indicator_id": "string",
"indicator_name": "string",
"indicator_description": "string",
"uri": "string",
"notes": "string"
}
]name[Optional ; Not repeatable ; String]
The name of the framework.abbreviation[Optional ; Not repeatable ; String]
The abreviation of the name of the framework.custodian[Optional ; Not repeatable ; String]
The name of the organization that is the official custodian of the framework.description[Optional ; Not repeatable ; String]
A brief description of the framework.goal_id[Optional ; Not repeatable ; String]
The identifier of the Goal that the indicator or series is associated with.goal_name[Optional ; Not repeatable ; String]
The name (label) of the Goal that the indicator or series is associated with.
goal_description[Optional ; Not repeatable ; String]
A brief description of the Goal that the indicator or series is associated with.target_id[Optional ; Not repeatable ; String]
The identifier of the Target that the indicator or series is associated with.target_name[Optional ; Not repeatable ; String]
The name (label) of the Target that the indicator or series is associated with.target_description[Optional ; Not repeatable ; String]
A brief description of the Target that the indicator or series is associated with.indicator_id[Optional ; Not repeatable ; String]
The identifier of the indicator, as provided in the framework (this is not theidnoidentifier).indicator_name[Optional ; Not repeatable ; String]
The name of the indicator, as provided in the framework (which may be different from the name provided inname)indicator_description[Optional ; Not repeatable ; String]
A brief description of the indicator, as provided in the framework.uri[Optional ; Not repeatable ; String]
A link to a website providing detailed information on the framework, its goals, targets, and indicators.notes[Optional ; Not repeatable ; String]
Any additional information on the relationship between the indicator/series and the framework.series_group[Optional ; Repeatable]
The group(s) the indicator belongs to. Groups can be create to organize indicators/series by theme, producer, or other.
"series_groups": [
{
"name": "string",
"description": "string",
"version": "string",
"uri": "string"
}
]name[Optional ; Not repeatable ; String]
The name of the group.description[Optional ; Not repeatable ; String]
A brief description of the group.version[Optional ; Not repeatable ; String]
The version of the grouping.uri[Optional ; Not repeatable ; String]
A link to a public website site where information on the grouping can be obtained.contacts[Optional ; Repeatable]
Thecontactselement provides the public interface for questions associated with the production of the indicator or time series.
"contacts": [
{
"name": "string",
"role": "string",
"affiliation": "string",
"email": "string",
"telephone": "string",
"uri": "string"
}
]name[Optional ; Not repeatable ; String]
The name of the contact person that should be contacted. Instead of the name of an individual (which would be subject to change and require frequent update of the metadata), a title can be provided here (e.g. “data helpdesk”).role[Optional ; Not repeatable ; String]
The specific role of the contact person mentioned inname. This will be used when multiple contacts are listed, and is intended to help users direct their questions and requests to the right contact person.
affiliation[Optional ; Not repeatable ; String]
The organization or affiliation of the contact person mentioned inname.email[Optional ; Not repeatable ; String]
The email address of the person or organization mentioned inname. Avoid using personal email accounts; the use of an anonymous email is recommended (e.g, “helpdesk@….org”)telephone[Optional ; Not repeatable ; String]
The phone number of the person or organization mentioned inname.uri[Optional ; Not repeatable ; String]
The URI of the agency (typically, a URL to a “contact us” web page).
8.2.2 Provenance
provenance [Optional ; Repeatable]
Metadata can be programmatically harvested from external catalogs. The provenance group of elements is used to store information on the provenance of harvested metadata, and on alterations that may have been made to the harvested metadata.
"provenance": [
{
"origin_description": {
"harvest_date": "string",
"altered": true,
"base_url": "string",
"identifier": "string",
"date_stamp": "string",
"metadata_namespace": "string"
}
}
]origin_description[Required ; Not repeatable]
Theorigin_descriptionelements are used to describe when and from where metadata have been extracted or harvested.harvest_date[Required ; Not repeatable ; String]
The date and time the metadata were harvested, entered in ISO 8601 format.altered[Optional ; Not repeatable ; Boolean]
A boolean variable (“true” or “false”; “true by default) indicating whether the harvested metadata have been modified before being re-published. In many cases, the unique identifier of the study (elementidnoin the Document Description / Title Statement section) will be modified when published in a new catalog.base_url[Required ; Not repeatable ; String]
The URL from where the metadata were harvested.identifier[Optional ; Not repeatable ; String]
The unique dataset identifier (idnoelement) in the source catalog. When harvested metadata are re-published in a new catalog, the identifier will likely be changed. Theidentifierelement inprovenanceis used to maintain traceability.date_stamp[Optional ; Not repeatable ; String]
The date stamp (in UTC date format) of the metadata record in the originating repository (this should correspond to the date the metadata were last updated in the source catalog).metadata_namespace[Optional ; Not repeatable ; String]
@@@@@@@
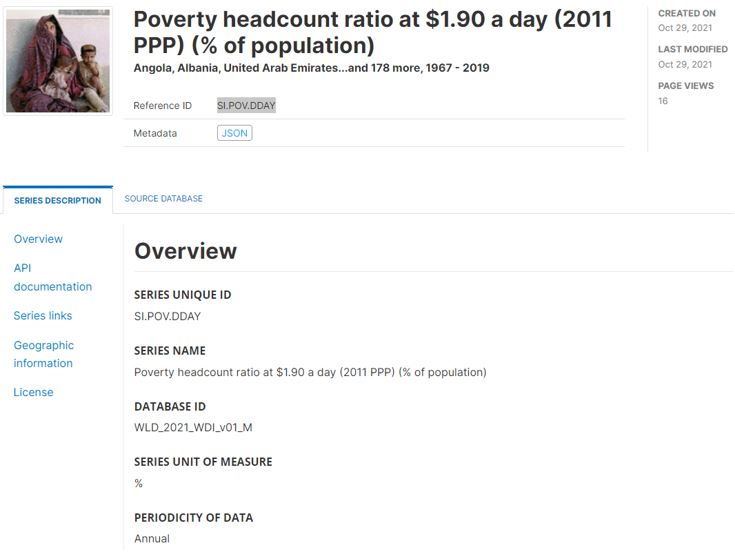
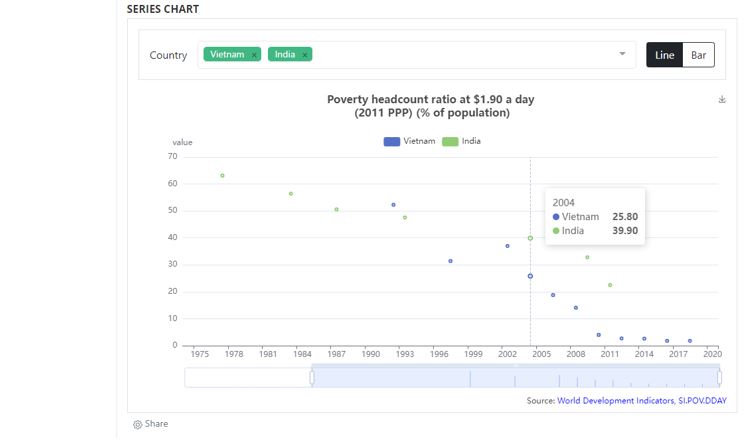
8.3 Generating and publishing compliant metadata - Complete example
We use a series from the World Bank’s World Development Indicators (WDI 2021) as an example: the series “Poverty headcount ratio at $1.90 a day (2011 PPP) (% of population)”
Note that we only show how metadata are generated and published in a NADA catalog. We do not demonstrate the (optional) publishing of the underlying data in a MongoDB database, which makes the data accessible via API and allows activation of data visualizations in the NADA catalog. This is covered in the NADA documentation.
8.3.1 Use of AI for metadata augmentation
The discoverability of indicators by keyword-based search engines can be significantly improved by the inclusion of a list of relevant keywords in the metadata. These keywords can be synonyms or terms and concepts that are closely associated with the indicator. Identifying the most relevant related keywords requires subject matter expertise. But this can be considerably facilitated by the use of AI tools. We provide below an example of a query submitted to chatGPT. The proposed terms returned by the application MUST be reviewed by a subject matter expert. But having the proposed list (which can be copy-pasted then edited in a Metadata Editor or in a script) will make the process very efficient.

image
The returned list is as follows: Poverty Headcount ratio Income Consumption Living standards Basic needs Poverty line Purchasing power parity (PPP) International poverty line Economic development Social inequality Human development Poverty reduction Extreme poverty Global poverty Developing countries Wealth distribution Rural poverty Urban poverty Household income Inclusive growth Multidimensional poverty Income inequality Poverty gap Human capital Poverty trap Food security Employment Vulnerability Social protection Poverty measurement Poverty alleviation Social exclusion Targeted interventions Poverty incidence Poverty dynamics Poverty cycle Equity Income distribution Sustainable development
8.3.2 Using R
# The code below generates metadata at the database level (object "wdi_database")
# and for a time series (object "this_series").
# It then publishes the metadata in a NADA catalog using the R package NADAR.
# It also publishes related materials as "external resources".
library(nadar)
# ----------------------------------------------------------------------------------
# Enter credentials (API confidential key) and catalog URL
my_keys <- read.csv("C:/confidential/my_API_keys.csv", header=F, stringsAsFactors=F)
set_api_key("my_keys[1,1")
set_api_url("https://.../index.php/api/")
set_api_verbose(FALSE)
# ----------------------------------------------------------------------------------
setwd("C:/my_indicators/")
thumb = "poverty.JPG" # Image to be used as thumbnail in the data catalog
db_id = "WB_WDI_2021_09_15" # The WDI database identifier
# Document the indicator (Poverty headcount ratio at $1.90 a day)
this_series = list(
metadata_creation = list(
producers = list(
list(name = "Development Data Group",
abbr = "DECDG",
affiliation = "World Bank",
role = "Metadata curation")
),
prod_date = "2021-10-15",
version = "Example v 1.0"
),
series_description = list(
idno = "SI.POV.DDAY",
name = "Poverty headcount ratio at $1.90 a day (2011 PPP) (% of population)",
database_id = db_id, # To attach the database metadata to the series metadata
measurement_unit = "% of population",
periodicity = "Annual",
definition_short = "Poverty headcount ratio at $1.90 a day is the percentage of the population living on less than $1.90 a day at 2011 international prices. As a result of revisions in PPP exchange rates, poverty rates for individual countries cannot be compared with poverty rates reported in earlier editions.",
definition_references = list(
list(source = "World Bank, Development Data Group",
uri = "https://databank.worldbank.org/metadataglossary/millennium-development-goals/series/SI.POV.DDAY"
)
),
methodology = "International comparisons of poverty estimates entail both conceptual and practical problems. Countries have different definitions of poverty, and consistent comparisons across countries can be difficult. Local poverty lines tend to have higher purchasing power in rich countries, where more generous standards are used, than in poor countries. Since World Development Report 1990, the World Bank has aimed to apply a common standard in measuring extreme poverty, anchored to what poverty means in the world's poorest countries. The welfare of people living in different countries can be measured on a common scale by adjusting for differences in the purchasing power of currencies. The commonly used $1 a day standard, measured in 1985 international prices and adjusted to local currency using purchasing power parities (PPPs), was chosen for World Development Report 1990 because it was typical of the poverty lines in low-income countries at the time. As differences in the cost of living across the world evolve, the international poverty line has to be periodically updated using new PPP price data to reflect these changes. The last change was in October 2015, when we adopted $1.90 as the international poverty line using the 2011 PPP. Prior to that, the 2008 update set the international poverty line at $1.25 using the 2005 PPP. Poverty measures based on international poverty lines attempt to hold the real value of the poverty line constant across countries, as is done when making comparisons over time. The $3.20 poverty line is derived from typical national poverty lines in countries classified as Lower Middle Income. The $5.50 poverty line is derived from typical national poverty lines in countries classified as Upper Middle Income. Early editions of World Development Indicators used PPPs from the Penn World Tables to convert values in local currency to equivalent purchasing power measured in U.S dollars. Later editions used 1993, 2005, and 2011 consumption PPP estimates produced by the World Bank. The current extreme poverty line is set at $1.90 a day in 2011 PPP terms, which represents the mean of the poverty lines found in 15 of the poorest countries ranked by per capita consumption. The new poverty line maintains the same standard for extreme poverty - the poverty line typical of the poorest countries in the world - but updates it using the latest information on the cost of living in developing countries. As a result of revisions in PPP exchange rates, poverty rates for individual countries cannot be compared with poverty rates reported in earlier editions. The statistics reported here are based on consumption data or, when unavailable, on income surveys. Analysis of some 20 countries for which income and consumption expenditure data were both available from the same surveys found income to yield a higher mean than consumption but also higher inequality. When poverty measures based on consumption and income were compared, the two effects roughly cancelled each other out: there was no significant statistical difference.",
limitation = "Despite progress in the last decade, the challenges of measuring poverty remain. The timeliness, frequency, quality, and comparability of household surveys need to increase substantially, particularly in the poorest countries. The availability and quality of poverty monitoring data remains low in small states, countries with fragile situations, and low-income countries and even some middle-income countries. The low frequency and lack of comparability of the data available in some countries create uncertainty over the magnitude of poverty reduction. Besides the frequency and timeliness of survey data, other data quality issues arise in measuring household living standards. The surveys ask detailed questions on sources of income and how it was spent, which must be carefully recorded by trained personnel. Income is generally more difficult to measure accurately, and consumption comes closer to the notion of living standards. And income can vary over time even if living standards do not. But consumption data are not always available: the latest estimates reported here use consumption data for about two-thirds of countries. However, even similar surveys may not be strictly comparable because of differences in timing or in the quality and training of enumerators. Comparisons of countries at different levels of development also pose a potential problem because of differences in the relative importance of the consumption of nonmarket goods. The local market value of all consumption in kind (including own production, particularly important in underdeveloped rural economies) should be included in total consumption expenditure but may not be. Most survey data now include valuations for consumption or income from own production, but valuation methods vary.",
topics = list(
list(id = "1",
name = "Economics, Consumption and consumer behaviour",
vocabulary = "",
uri = "https://vocabularies.cessda.eu/vocabulary/TopicClassification"),
list(id = "2",
name = "Economics, Economic conditions and indicators",
vocabulary = "CESSDA Version 4.1",
uri = "https://vocabularies.cessda.eu/vocabulary/TopicClassification"),
list(id = "3",
name = "Economics, Economic systems and development",
vocabulary = "CESSDA Version 4.1",
uri = "https://vocabularies.cessda.eu/vocabulary/TopicClassification"),
list(id = "4",
name = "Social stratification and groupings, Equality, inequality and social exclusion",
vocabulary = "CESSDA Version 4.1",
uri = "https://vocabularies.cessda.eu/vocabulary/TopicClassification")
),
relevance = "The World Bank Group is committed to reducing extreme poverty to 3 percent or less, globally, by 2030. Monitoring poverty is important on the global development agenda as well as on the national development agenda of many countries. The World Bank produced its first global poverty estimates for developing countries for World Development Report 1990: Poverty (World Bank 1990) using household survey data for 22 countries (Ravallion, Datt, and van de Walle 1991). Since then there has been considerable expansion in the number of countries that field household income and expenditure surveys. The World Bank's Development Research Group maintains a database that is updated annually as new survey data become available (and thus may contain more recent data or revisions) and conducts a major reassessment of progress against poverty every year. PovcalNet is an interactive computational tool that allows users to replicate these internationally comparable $1.90, $3.20 and $5.50 a day global, regional and country-level poverty estimates and to compute poverty measures for custom country groupings and for different poverty lines. The Poverty and Equity Data portal provides access to the database and user-friendly dashboards with graphs and interactive maps that visualize trends in key poverty and inequality indicators for different regions and countries. The country dashboards display trends in poverty measures based on the national poverty lines alongside the internationally comparable estimates, produced from and consistent with PovcalNet.",
time_periods = list(list(start = "1960", end = "2020")),
geographic_units = list(
list(name = "Afghanistan", code = "AFG", type = "country/economy"),
list(name = "Africa Eastern and Southern", code = "AFE", type = "geographic region"),
list(name = "Africa Western and Central", code = "AFW", type = "geographic region"),
list(name = "Albania", code = "ALB", type = "country/economy"),
list(name = "Algeria", code = "DZA", type = "country/economy"),
list(name = "Angola", code = "AGO", type = "country/economy"),
list(name = "Aruba", code = "ABW", type = "country/economy")
# ... and many more - In a real situation, this would be programmatically extracted from the data
),
license = list(name = "CC BY-4.0", uri = "https://creativecommons.org/licenses/by/4.0/"),
api_documentation = list(
description = "See the Developer Information webpage for detailed documentation of the API",
uri = "https://datahelpdesk.worldbank.org/knowledgebase/topics/125589-developer-information"
),
source = "World Bank, Development Data Group (DECDG) and Poverty and Inequality Global Practice. Data are based on primary household survey data obtained from government statistical agencies and World Bank country departments. Data for high-income economies are from the Luxembourg Income Study database. For more information and methodology, see PovcalNet website: http://iresearch.worldbank.org/PovcalNet/home.aspx",
keywords = list(
list(name = "poverty rate"),
list(name = "poverty incidence"),
list(name = "global poverty line"),
list(name = "international poverty line"),
list(name = "welfare"),
list(name = "prosperity"),
list(name = "inequality"),
list(name = "income")
),
acronyms = list(
list(acronym = "PPP", expansion = "Purchasing Power Parity")
),
related_indicators = list(
list(code = "SI.POV.GAPS",
label = "Poverty gap at $1.90 a day (2011 PPP) (%)",
uri = "https://databank.worldbank.org/source/millennium-development-goals/Series/SI.POV.GAPS"),
list(code = "SI.POV.NAHC",
label = "Poverty headcount ratio at national poverty lines (% of population)",
uri = "https://databank.worldbank.org/source/millennium-development-goals/Series/SI.POV.NAHC")
),
framework = list(
list(name = "Sustainable Development Goals (SDGs)",
description = "The 2030 Agenda for Sustainable Development, adopted by all United Nations Member States in 2015, provides a shared blueprint for peace and prosperity for people and the planet, now and into the future. At its heart are the 17 Sustainable Development Goals (SDGs), which are an urgent call for action by all countries - developed and developing - in a global partnership.",
goal_id = "SDG Goal 1",
goal_name = "End poverty in all its forms everywhere",
target_id = "SDG Target 1.1",
target_name = "By 2030, eradicate extreme poverty for all people everywhere, currently measured as people living on less than $1.25 a day",
indicator_id = "SDG Indicator 1.1.1",
indicator_name = "Proportion of population below the international poverty line, by sex, age, employment status and geographical location (urban/rural)",
uri = "https://sdgs.un.org/goals")
)
)
)
# Publish the metadata in NADA, with a link to the WDI website
# Database-level metadata
timeseries_database_add(idno = db_id,
published = 1,
overwrite = "yes",
metadata = wdi_database)
# Indicator-level metadata
timeseries_add(
idno = this_series$series_description$idno,
repositoryid = "central",
published = 1,
overwrite = "yes",
metadata = this_series,
thumbnail = thumb
)
# Add a link to the WDI website as an external resource
external_resources_add(
title = "World Development Indicators website",
idno = this_series$series_description$idno,
dctype = "web",
file_path = "https://datatopics.worldbank.org/world-development-indicators/",
overwrite = "yes"
)After uploading the above metadata, and activating some visualization widgets, the result in NADA will be as follows (not all metadata displayed here; see https://nada-demo.ihsn.org/index.php/catalog/study/SI.POV.DDAY for the full view):