Chapter 11 Videos
The schema we propose to document video files is a combination of elements extracted from the Dublin Core Metadata Initiative (DCMI) and from the VideoObject (from schema.org) schemas. This schema is very similar to the schema we proposed for audio files (see chapter 10).
The Dublin Core is a generic and versatile standard, which we also use (in an augmented form) for the documentation of Documents (Chapter 4), Images (Chapter 9), and Audio files (chapter 10). It contains 15 core elements, to which we added a selection of elements from VideoObject. We also included the elements keywords, topics, tags, provenance and additional that are found in other schemas documented in the Guide.
The resulting metadata schema is simple, but it contains the elements needed to document the resources and their content in a way that will foster their discoverability in data catalogs. Compliance with the VideoObject elements contributes to search engine optimization, as search engines like Google, Bing and others “reward” metadata published in formats compatible with the schema.org recommendations.
{
"repositoryid": "string",
"published": 0,
"overwrite": "no",
"metadata_information": {},
"video_description": {},
"provenance": [],
"tags": [],
"lda_topics": [],
"embeddings": [],
"additional": { }
}When published in a NADA catalog, the metadata related to video files will appear in a specific tab.

11.1 Augmenting video metadata
Videos typically come with limited metadata. To make them more discoverable, a transcription of the video content can be generated, stored, and indexed in the catalog. The metadata schema we propose includes an element transcription that can store transcriptions (and possibly their automatically-generated translations) in the video metadata. Word embedding models and topic models can be applied to the transcriptions to further augment the metadata. This will significantly increase the discoverability of the resource, and offer the possibility to apply semantic searchability on video metadata.
Machine learning speech-to-text solutions are available (although not for all languages) to automatically generate transcriptions at a low cost. This includes commercial applications like Whisper by openAI, Microsoft Azure, or Amazon Transcribe. Open source solutions in Python also exist.
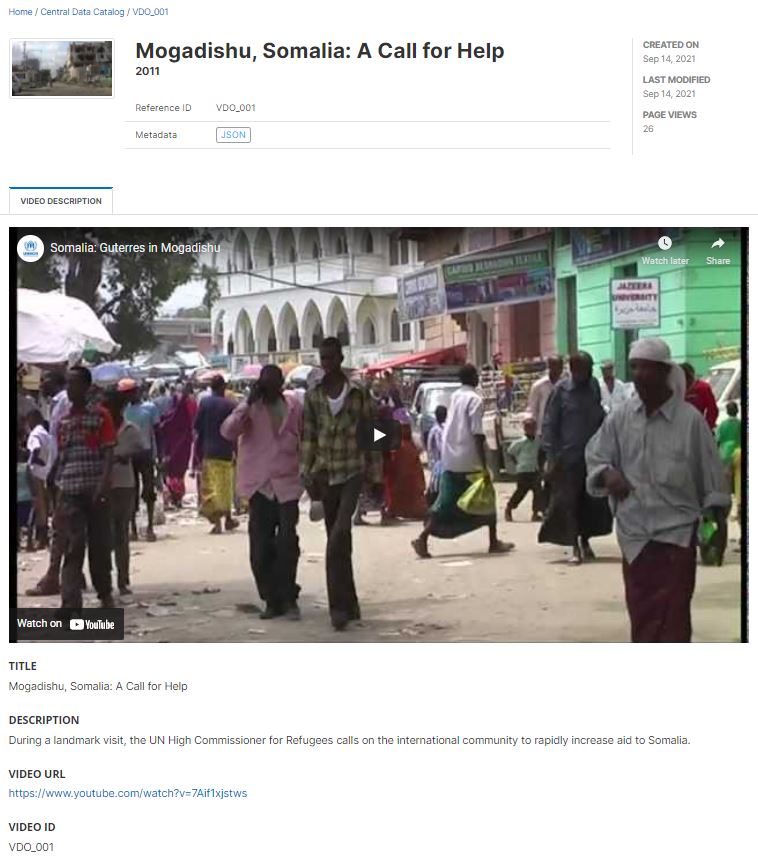
Transcriptions of videos published on Youtube are available on-line (the example below was extracted from https://www.youtube.com/watch?v=Axs8NPVYmms).
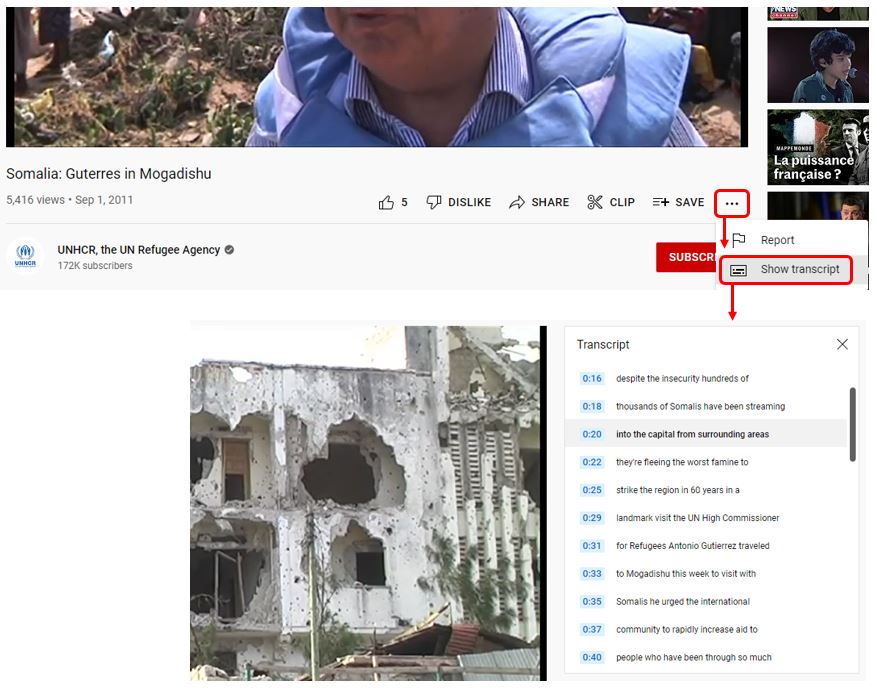
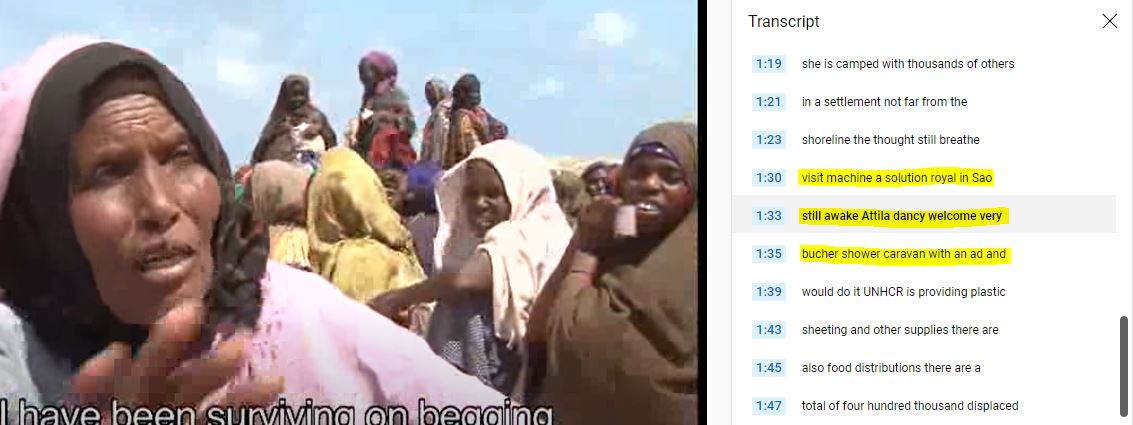
Note that some care must be taken when adding automatic speech transcriptions into your metadata, as the transcriptions are not always perfect and may return unexpected results. This will be the case when the sound quality is low, or when the video includes sections in an unknown language (see the example below, of a video in English that includes a brief segmnent in Somali; the speech-to-text algorithm may in such case attempt to transcribe text it does not recognize, returning invalid information).
11.2 Schema description
The first three elements of the schema (repositoryid, published, and overwrite) are not part of the video metadata. They are parameters used to indicate how the video metadata will be published in a NADA catalog.
repositoryididentifies the collection in which the metadata will be published. By default, the metadata will be published in the central catalog. To publish them in a collection, the collection must have been previously created in NADA.published: Indicates whether the metadata must be made visible to visitors of the catalog. By default, the value is 0 (unpublished). This value must be set to 1 (published) to make the metadata visible.overwrite: Indicates whether metadata that may have been previously uploaded for the same video can be overwritten. By default, the value is “no”. It must be set to “yes” to overwrite existing information. Note that a video will be considered as being the same as a previously uploaded one if the identifier provided in the metadata elementvideo_description > idnois the same.
11.2.1 Metadata information
metadata_information [Optional ; Not Repeatable]
The metadata information set is used to document the video metadata (not the video itself). This provides information useful for archiving purposes. This set is optional. It is recommended however to enter at least the identification and affiliation of the metadata producer, and the date of creation of the metadata. One reason for this is that metadata can be shared and harvested across catalogs/organizations, so metadata produced by one organization can be found in other data centers.
"metadata_information": {
"title": "string",
"idno": "string",
"producers": [
{
"name": "string",
"abbr": "string",
"affiliation": "string",
"role": "string"
}
],
"production_date": "string",
"version": "string"
}title[Optional ; Not Repeatable ; String]
The title of the video.idno[Optional ; Not Repeatable ; String]
A unique identifier for the metadata document (unique in the catalog; ideally also unique globally). This is different from the video unique ID (seeidnoelement in section video_description below), although it is good practice to generate identifiers that would maintain an easy connection between the metadataidnoelement and the videoidnofound undervideo_description(see below).producers[Optional ; Repeatable]
This refers to the producer(s) of the metadata, NOT to the producer(s) of the video. This could for example be the data curator in a data center.name[Optional ; Not repeatable ; String]
Name of the metadata producer/curator. An alternative to entering the name of the curator (e.g. for privacy protection purpose) is to enter the curator ID (see the element abbr below)abbr[Optional ; Not repeatable ; String]
Can be used to provide an ID of the metadata producer/curator.affiliation[Optional ; Not repeatable ; String]
Affiliation of the metadata producer/curator.role[Optional ; Not repeatable ; String]
Specific role of the metadata producer/curator.
production_date[Optional ; Not repeatable ; String]
Date the metadata (not the table) was produced.version[Optional ; Not repeatable ; String]
Version of the metadata (not version of the table).
11.2.2 Video description
video_description [Required ; Not Repeatable]
The video_description section contains all elements that will be used to describe the video and its content. These are the elements that will be indexed and made searchable when published in a data catalog.
idno[Mandatory, Not Repeatable ; String]
idnois an identification number that is used to uniquely identify a video in a catalog. It will also help users of the data cite the video properly. The best option is to obtain a Digital Object Identifier (DOI) for the video, as it will ensure that the ID is unique globally. Alternatively, it can be an identifier constructed by an organization using a consistent scheme. Note that the schema allows you to provide more than one identifier for a video (seeidentifiersbelow). This element maps to the “identifier” element in the Dublin Core.identifiers[Optional ; Repeatable]
"identifiers": [
{
"type": "string",
"identifier": "string"
}
]This element is used to enter video identifiers other than the idno element described above). It can for example be a Digital Object Identifier (DOI). Note that the identifier entered in idno can be repeated here, allowing to attach a “type” attribute to it.
- type [Optional ; Not repeatable ; String]
The type of unique identifier, e.g., “DOI”.
- value [Required ; Not repeatable ; String]
The identifier.
title[Required ; Not repeatable ; String]The title of the video. This element maps to the element caption in VideoObject.
alt_title[Optional ; Not repeatable ; String]An alias for the video title. This element maps to the element alternateName in VideoObject.
description[Optional ; Not repeatable ; String]A brief description of the video, typically about a paragraph long (around 150 to 250 words). This element maps to the element abstract in VideoObject.
genre[Optional ; Repeatable ; String]The genre of the video, broadcast channel or group. This is a VideoObject element. A controlled vocabulary can be used.
keywords[Optional ; Repeatable]
"keywords": [
{
"name": "string",
"vocabulary": "string",
"uri": "string"
}
]A list of keywords that provide information on the core content of the video. Keywords provide a convenient solution to improve the discoverability of the video, as it allows terms and phrases not found elsewhere in the video metadata to be indexed and to make the video discoverable by text-based search engines. A controlled vocabulary will preferably be used (although not required), such as the UNESCO Thesaurus. The list can combine keywords from multiple controlled vocabularies, and user-defined keywords.
- name [Required ; Not repeatable ; String]
The keyword itself.
- vocabulary [Optional ; Not repeatable ; String]
The controlled vocabulary (including version number or date) from which the keyword is extracted, if any.
- uri [Optional ; Not repeatable ; String]
The URL of the controlled vocabulary from which the keyword is extracted, if any.
my_video <- list(
# ... ,
video_description = list(
# ... ,
keywords = list(
list(name = "Migration",
vocabulary = "Unesco Thesaurus (June 2021)",
uri = "http://vocabularies.unesco.org/browser/thesaurus/en/page/concept427"),
list(name = "Migrants",
vocabulary = "Unesco Thesaurus (June 2021)",
uri = "http://vocabularies.unesco.org/browser/thesaurus/en/page/concept427"),
list(name = "Refugee",
vocabulary = "Unesco Thesaurus (June 2021)",
uri = "http://vocabularies.unesco.org/browser/thesaurus/en/page/concept427"),
list(name = "Forced displacement"),
list(name = "Internally displaced population (IDP)")
),
# ...
),
# ...
) topics[Optional ; Repeatable]
"topics": [
{
"id": "string",
"name": "string",
"parent_id": "string",
"vocabulary": "string",
"uri": "string"
}
]Information on the topics covered in the video. A controlled vocabulary will preferably be used, for example the CESSDA Topics classification, a typology of topics available in 11 languages; or the Journal of Economic Literature (JEL) Classification System, or the World Bank topics classification. Note that you may use more than one controlled vocabulary. This element is a block of five fields:
id[Optional ; Not repeatable ; String]
The identifier of the topic, taken from a controlled vocabulary.name[Required ; Not repeatable ; String]
The name (label) of the topic, preferably taken from a controlled vocabulary.parent_id[Optional ; Not repeatable ; String]
The parent identifier of the topic (identifier of the item one level up in the hierarchy), if a hierarchical controlled vocabulary is used.vocabulary[Optional ; Not repeatable ; String]
The name (including version number) of the controlled vocabulary used, if any.uri[Optional ; Not repeatable ; String]
The URL to the controlled vocabulary used, if any.
my_video <- list(
# ... ,
video_description = list(
# ... ,
topics = list(
list(name = "Demography.Migration",
vocabulary = "CESSDA Topic Classification",
uri = "https://vocabularies.cessda.eu/vocabulary/TopicClassification"),
list(name = "Demography.Censuses",
vocabulary = "CESSDA Topic Classification",
uri = "https://vocabularies.cessda.eu/vocabulary/TopicClassification"),
list(id = "F22",
name = "International Migration",
parent_id = "F2 - International Factor Movements and International Business",
vocabulary = "JEL Classification System",
uri = "https://www.aeaweb.org/econlit/jelCodes.php?view=jel#J"),
list(id = "O15",
name = "Human Resources - Human Development - Income Distribution - Migration",
parent_id = "O1 - Economic Development",
vocabulary = "JEL Classification System",
uri = "https://www.aeaweb.org/econlit/jelCodes.php?view=jel#J"),
list(id = "O12",
name = "Microeconomic Analyses of Economic Development",
parent_id = "O1 - Economic Development",
vocabulary = "JEL Classification System",
uri = "https://www.aeaweb.org/econlit/jelCodes.php?view=jel#J"),
list(id = "J61",
name = "Geographic Labor Mobility - Immigrant Workers",
parent_id = "J6 - Mobility, Unemployment, Vacancies, and Immigrant Workers",
vocabulary = "JEL Classification System",
uri = "https://www.aeaweb.org/econlit/jelCodes.php?view=jel#J")
),
# ...
),
) persons[Optional ; Repeatable]
"persons": [
{
"name": "string",
"role": "string"
}
]A list of persons who appear in the video.
- name [Required ; Not repeatable ; String]
The name of the person.
- role [Optional ; Not repeatable, String]
The role of the person mentioned in name.
my_video <- list(
metadata_information = list(
# ...
),
video_description = list(
# ... ,
persons = list(
list(name = "John Smith",
role = "Keynote speaker"),
list(name = "Jane Doe",
role = "Debate moderator")
),
# ...
) main_entity[Optional ; Not repeatable ; String]Indicates the primary entity described in the video. This element maps to the element
mainEntityin VideoObject.date_created[Optional, Not Repeatable ; String]The date the video was created. It is recommended to enter the date in the ISO 8601 format (YYYY-MM-DD or YYYY-MM or YYYY). The date the video is created refers to the date that the video was produced and considered ready for dissemination.
date_published[Optional, Not Repeatable ; String]The date the video was published. It is recommended to use the ISO 8601 format (YYYY-MM-DD or YYYY-MM or YYYY).
version[Optional, Not Repeatable ; String]The version of the video refers to the published version of the video.
status[Optional ; Not repeatable, String]The status of the video in terms of its stage in a lifecycle. A controlled vocabulary should be used. Example terms include {
Incomplete, Draft, Published, Obsolete}. Some organizations define a set of terms for the stages of their publication lifecycle. This element maps to the element creativeWorkStatus in VideoObject.country[Optional ; Repeatable]
"country": [
{
"name": "string",
"code": "string"
}
]The list of countries (or regions) covered by the video, if applicable. This refers to the content of the video, not to the country where the video was released. This is a repeatable block of two elements:
- name [Required ; Not repeatable ; String]
The country/region name. Note that many organizations have their own policies on the naming of countries/regions/economies/territories, which data curators will have to comply with.
- code [Optional ; Not repeatable ; String]
The country/region code (entered as a string, even for numeric codes). It is recommended to use a standard list of countries and regions, such as the ISO country list (ISO 3166).
spatial_coverage[Optional ; Not repeatable ; String]Indicates the place(s) which are depicted or described in the video. This element maps to the element
contentLocationin VideoObject. This element complements theref_countryelement. It can be used to qualify the geographic coverage of the video, in the form of a free text.content_reference_time[Optional ; Not repeatable ; String]The specific time described by the video, for works that emphasize a particular moment within an event. This element maps to the element
contentReferenceTimein VideoObject.temporal_coverage[Optional ; Not repeatable ; String]Indicates the period that the video applies to, i.e. that it describes, either as a DateTime or as a textual string indicating a time period in ISO 8601 time interval format. This element maps to the element
temporalCoveragein VideoObject.recorded_at[Optional ; Not repeatable ; String]This element maps to the element
recordedAtin VideoObject schema. It identifies the event where the video was recorded (e.g., a conference, or a demonstration).audience[Optional ; Not repeatable ; String]
A brief description of the intended audience of the video, i.e. the group for whom it was created.
bbox[Optional ; Repeatable]
"bbox": [
{
"west": "string",
"east": "string",
"south": "string",
"north": "string"
}
]This element is used to define one or multiple bounding box(es), which are the (rectangular) fundamental geometric description of the geographic coverage of the video. A bounding box is defined by west and east longitudes and north and south latitudes, and includes the largest geographic extent of the video’s geographic coverage. The bounding box provides the geographic coordinates of the top left (north/west) and bottom-right (south/east) corners of a rectangular area. This element can be used in catalogs as the first pass of a coordinate-based search.
- west [Required ; Not repeatable ; String]
West longitude of the box
- east [Required ; Not repeatable ; String]
East longitude of the box
- south [Required ; Not repeatable ; String]
South latitude of the box
- north [Required ; Not repeatable ; String]
North latitude of the box
language[Optional, Repeatable]
"language": [
{
"name": "string",
"code": "string"
}
]Most videos will only be provided in one language. This is however a repeatable field, to allow for more than one language to be listed. For the language code, ISO codes will preferably be used. The language refers to the language in which the video is published. This is a block of two elements (at least one must be provided for each language):
- name [Optional ; Not repeatable ; String]
The name of the language.
- code [Optional ; Not repeatable ; String]
The code of the language. The use of ISO 639-2 (the alpha-3 code in Codes for the representation of names of languages) is recommended. Numeric codes must be entered as strings.
creator[Optional, Not repeatable ; String]
Organization or person who created/authored the video.
production_company[Optional, Not repeatable ; String]The production company or studio responsible for the item. This element maps to the element productionCompany in VideoObject.
publisher[Optional, Not repeatable ; String]my_video = list( # ... , video_description = list( # ... , publisher = "@@@@@", # ... ) )repository[Optional ; Not repeatable ; String]The name of the repository (organization).
contacts[Optional, Repeatable]
Users of the video may need further clarification and information. This section may include the name-affiliation-email-URI of one or multiple contact persons. This block of elements will identify contact persons who can be used as resource persons regarding problems or questions raised by the user community. The URI attribute should be used to indicate a URN or URL for the homepage of the contact individual. The email attribute is used to indicate an email address for the contact individual. It is recommended to avoid putting the actual name of individuals. The information provided here should be valid for the long term. It is therefore preferable to identify contact persons by a title. The same applies for the email field. Ideally, a “generic” email address should be provided. It is easy to configure a mail server in such a way that all messages sent to the generic email address would be automatically forwarded to some staff members.
"contacts": [
{
"name": "string",
"role": "string",
"affiliation": "string",
"email": "string",
"telephone": "string",
"uri": "string"
}
]name[Required, Not repeatable, String]
Name of a person or unit (such as a data help desk). It will usually be better to provide a title/function than the actual name of the person. Keep in mind that people do not stay forever in their position.role[Optional, Not repeatable, String]
The specific role ofname, in regards to supporting users. This element is used when multiple names are provided, to help users identify the most appropriate person or unit to contact.affiliation[Optional, Not repeatable, String]
Affiliation of the person/unit.email[Optional, Not repeatable, String]
E-mail address of the person.telephone[Optional, Not repeatable, String]
A phone number that can be called to obtain information or provide feedback on the table. This should never be a personal phone number; a corporate number (typically of a data help desk) should be provided.uri[Optional, Not repeatable, String]
A link to a website where contact information fornamecan be found.contributors[Optional, Repeatable]
"contributors": [
{
"name": "string",
"affiliation": "string",
"abbr": "string",
"role": "string",
"uri": "string"
}
]Identifies the person(s) and/or organization(s) who contributed to the production of the video. The role attribute allows defining what the specific contribution of the identified person or organization was.
- name [Optional, Not Repeatable ; String]
The name of the contributor (person or organization).
- affiliation [Optional, Not Repeatable ; String]
The affiliation of the contributor.
- abbr [Optional, Not Repeatable ; String]
The abbreviation for the institution which has been listed as the affiliation of the contributor.
- role [Optional, Not Repeatable ; String]
The specific role of the contributor. This could for example be “Cameraman”, “Sound engineer”, etc.
- uri [Optional, Not Repeatable ; String]
A URI (link to a website, or email address) for the contributor.
my_video = list(
# ... ,
video_description = list(
# ... ,
contributors = list(
list(
name = "",
affiliation = "",
abbr = "",
role = "",
uri = "")
),
# ...
)
)sponsors[Optional ; Repeatable]
"sponsors": [
{
"name": "string",
"abbr": "string",
"grant": "string",
"role": "string"
}
]This element is used to list the funders/sponsors of the video. If different funding agencies financed different stages of the production process, use the “role” attribute to distinguish them.
- name [Required ; Not repeatable ; String]
The name of the sponsor (person or organization)
- abbr [Optional ; Not repeatable ; String]
The abbreviation (acronym) of the sponsor.
- grant [Optional ; Not repeatable ; String]
The grant (or contract) number.
- role [Optional ; Not repeatable ; String]
The specific role of the sponsor.
translators[Optional ; Repeatable]
"translators": [
{
"first_name": "string",
"initial": "string",
"last_name": "string",
"affiliation": "string"
}
]Organization or person who adapted the video to different languages. This element maps to the element translator in VideoObject.
- first_name [Optional ; Not repeatable ; String]
The first name of the translator.
- initial [Optional ; Not repeatable ; String]
The initials of the translator.
- last_name [Optional ; Not repeatable ; String]
The last name of the translator.
- affiliation [Optional ; Not repeatable ; String]
The affiliation of the translator.
is_based_on[Optional ; Not repeatable, String]A resource from which this video is derived or from which it is a modification or adaption. This element maps to the element isBasedOn in VideoObject.
is_part_of[Optional ; Not repeatable, String]Indicates another video that this video is part of. This element maps to the element isPartOf in VideoObject.
relations[Optional ; Repeatable, String]
"relations": [
"string"
]Defines, as a free text field, the relation between the video being documented and other resources. This is a Dublin Core element.
video_provider[Optional ; Not repeatable, String]

The person or organization who provides the video. This element maps to the element provider in VideoObject.
video_url[Optional ; Not repeatable, String]URL of the video. This element maps to the element url in VideoObject.
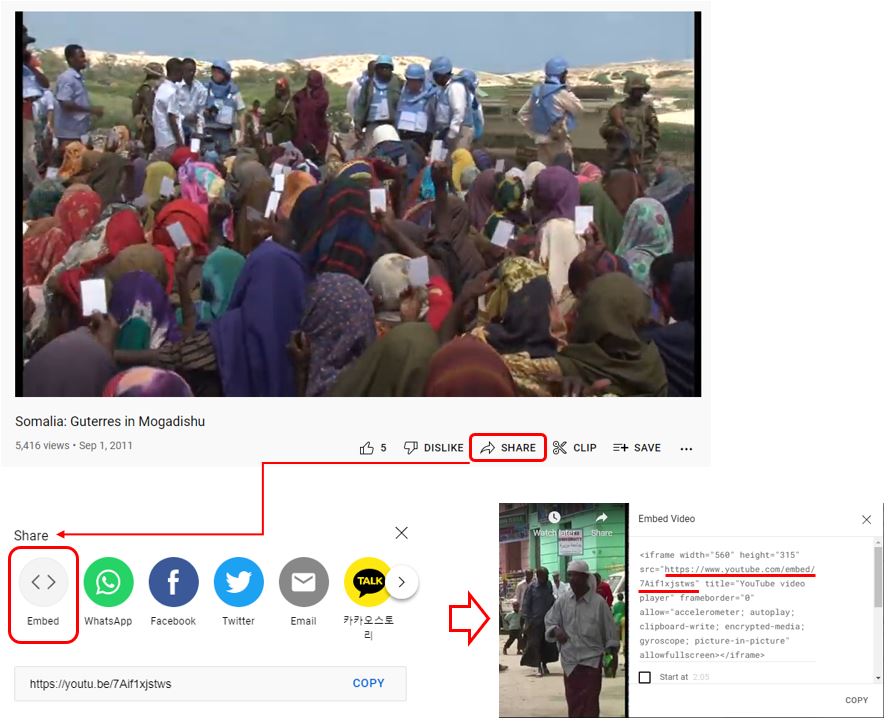
embed_url[Optional ; Not repeatable, String]A URL pointing to a player for a specific video. This element maps to the element embedUrl in VideoObject. For example, “https://www.youtube.com/embed/7Aif1xjstws”
To be embedded, a video must be hosted on a video sharing platform like Youtube (www.youtube.com). To obtain the “embed link” from youtube, click on the “Share” button, then “Embed”. In the result box, select the content of the element
src =.
encoding_format[Optional ; Not repeatable, String]The video file format, typically expressed using a MIME format. This element corresponds to the “encodingFormat” element of VideoObject and maps to the element format of the Dublin Core.
duration[Optional ; Not repeatable, String]The duration of the item (movie, audio recording, event, etc.) in ISO 8601 format. This element is a VideoObject element.
ISO 8601 durations are expressed using the following format, where (n) is replaced by the value for each of the date and time elements that follows the (n). For example: (3)H means 3 hours.
Where:P(n)Y(n)M(n)DT(n)H(n)M(n)S
- P is the Period designator and is always placed at the beginning of the duration
- (n)Y represents the number of years
- (n)M represents the number of months
- (n)W represents the number of weeks
- (n)D represents the number of days
- T is the Time designator and always precedes the time components
- (n)H represents the number of hours
- (n)M represents the number of minutes
- (n)S represents the number of seconds
For example, P1Y2M20DT3H30M8S represents a duration of one year, two months, twenty days, three hours, thirty minutes, and eight seconds.
Date and time elements including their designator may be omitted if their value is zero, and lower-order elements may also be omitted for reduced precision. For example, “P23DT23H” and “P4Y” are both acceptable duration representations.
As M can represent both Month and Minutes, the time designator T is used. For example, “P1M” is a one-month duration and “PT1M” is a one-minute duration.
This information on the ISO 8601 was adapted from wikipedia where more detailed information can be found.
- P is the Period designator and is always placed at the beginning of the duration
rights[Optional ; Not repeatable, String]A textual description of the rights associated to the video. If a copyright is available, the three following elements will be used instead of this element.
copyright_holder[Optional ; Not repeatable, String]The party holding the legal copyright to the video. This element corresponds to the “copyrightHolder” element of VideoObject.
copyright_notice[Optional ; Not repeatable, String]Text of a notice appropriate for describing the copyright aspects of the video, ideally indicating the owner of the copyright. This element corresponds to the “copyrightNotice” element of VideoObject.
copyright_year[Optional ; Not repeatable, String]The year during which the claimed copyright for the video was first asserted. This element corresponds to the “copyrightYear” element of VideoObject.
credit_text[Optional ; Not repeatable, String]This element can be used to credit the person(s) and/or organization(s) associated with a published video. This element corresponds to the “creditText” element of VideoObject.
citation[Optional ; Not repeatable, String]This element provides a required or recommended citation of the audio file.
transcript[Optional ; Repeatable, String]
"transcript": [
{
"language_name": "string",
"language_code": "string",
"text": "string"
}
]The transcript of the video content, provided as a text. Note that if the text is very long, an alternative is to save it in a separate text file and to make it available in a data catalog as an external resource.
- language_name [Optional ; Not repeatable ; String]
The name of the language of the transcript.
- language_code [Optional ; Not repeatable ; String]
The code of the language of the transcript, preferably the ISO code.
- text [Optional ; Not repeatable ; String]
The transcript itself. Adding the transcript in the metadata will make the video much more discoverable, as the content of the transcription can be indexed in catalogs.
media[Optional ; Repeatable ; String]
"media": [
"string"
]A description of the media on which the recording is stored (other than the online file format); e,g., “CD-ROM”.
album[Optional ; Repeatable]
"album": [
{
"name": "string",
"description": "string",
"owner": "string",
"uri": "string"
}
]When a video is published in a catalog containing many other videos, it may be desirable to organize them by album. Albums are collections of videos organized by theme, period, location, or other criteria. One video can belong to more than one album. Albums are “virtual collections”.
- name [Optional ; Not Repeatable ; String]
The name (label) of the album.
- description [Optional ; Not Repeatable ; String]
A brief description of the album.
- owner [Optional ; Not Repeatable ; String]
The owner of the album.
- uri [Optional ; Not Repeatable ; String]
A link (URL) to the album.
provenance[Optional ; Repeatable]Metadata can be programmatically harvested from external catalogs. The
provenancegroup of elements is used to store information on the provenance of harvested metadata, and on alterations that may have been done to the harvested metadata. These elements are NOT part of the IPTC or DCMI metadata standard.
"provenance": [ { "origin_description": { "harvest_date": "string", "altered": true, "base_url": "string", "identifier": "string", "date_stamp": "string", "metadata_namespace": "string" } } ]origin_description[Required ; Not repeatable]
Theorigin_descriptionelements are used to describe when and from where metadata have been extracted or harvested.harvest_date[Required ; Not repeatable ; String]
The date and time the metadata were harvested, in ISO 8601 format.altered[Optional ; Not repeatable ; Boolean]
A boolean variable (“true” or “false”; “true by default) indicating whether the harvested metadata have been modified before being re-published. In many cases, the unique identifier of the study (elementidnoin the Study Description / Title Statement section) will be modified when published in a new catalog.base_url[Required ; Not repeatable ; String]
The URL from where the metadata were harvested.identifier[Optional ; Not repeatable ; String]
The unique dataset identifier (idnoelement) in the source catalog. When harvested metadata are re-published in a new catalog, the identifier will likely be changed. Theidentifierelement inprovenanceis used to maintain traceability.date_stamp[Optional ; Not repeatable ; String]
The datestamp (in UTC date format) of the metadata record in the originating repository (this should correspond to the date the metadata were last updated in the source catalog).metadata_namespace[Optional ; Not repeatable ; String]
@@@@@@@
tags[Optional ; Repeatable]
As shown in section 1.7 of the Guide, tags, when associated withtag_groups, provide a powerful and flexible solution to enable custom facets (filters) in data catalogs. See section 1.7 for an example in R.
"tags": [
{
"tag": "string",
"tag_group": "string"
}
]tag[Required ; Not repeatable ; String]
A user-defined tag.tag_group[Optional ; Not repeatable ; String]
A user-defined group (optional) to which the tag belongs. Grouping tags allows implementation of controlled facets in data catalogs.lda_topics[Optional ; Not repeatable]We mentioned in Chapter 1 the importance of producing rich metadata, and the opportunities that machine learning offers to enrich (or “augment”) metadata in a largely automated manner. One application of machine learning, more specifically of natural language processing, to enrich metadata related to publications is the topic extraction using Latent Dirichlet Allocation (LDA) models. LDA models must be trained on large corpora of documents. They do not require any pre-defined taxonomy of topics. The approach consists of “clustering” words that are likely to appear in similar contexts (the number of “clusters” or “topics” is a parameter provided when training a model). Clusters of related words form “topics”. A topic is thus defined by a list of keywords, each one of them provided with a score indicating its importance in the topic. Typically, the top 10 words that represent a topic will be used to describe it. The description of the topics covered by a document can be indexed to improve searchability (possibly in a selective manner, by setting thresholds on the topic shares and word weights).
Once an LDA topic model has been trained, it can be used to infer the topic composition of any text. In the case of indicators and time series, this text will be a concatenation of some metadata elements including the series’ name, definitions, keywords, concepts, and possibly others. This inference will then provide the share that each topic represents in the metadata. The sum of all represented topics is 1 (100%).
"lda_topics": [
{
"model_info": [
{
"source": "string",
"author": "string",
"version": "string",
"model_id": "string",
"nb_topics": 0,
"description": "string",
"corpus": "string",
"uri": "string"
}
],
"topic_description": [
{
"topic_id": null,
"topic_score": null,
"topic_label": "string",
"topic_words": [
{
"word": "string",
"word_weight": 0
}
]
}
]
}
]The lda_topics element includes the following metadata fields.
model_info[Optional ; Not repeatable]
Information on the LDA model.source[Optional ; Not repeatable ; String]
The source of the model (typically, an organization).author[Optional ; Not repeatable ; String]
The author(s) of the model.version[Optional ; Not repeatable ; String]
The version of the model, which could be defined by a date or a number.model_id[Optional ; Not repeatable ; String]
The unique ID given to the model.nb_topics[Optional ; Not repeatable ; Numeric]
The number of topics in the model (the number of topics to be extracted from a corpus is the key parameter of any LDA model).description[Optional ; Not repeatable ; String]
A brief description of the model.corpus[Optional ; Not repeatable ; String]
A brief description of the corpus on which the LDA model was trained.uri[Optional ; Not repeatable ; String]
A link to a web page where additional information on the model is available.
topic_description[Optional ; Repeatable]
The topic composition extracted from selected elements of the series metadata (typically, the name, definitions, and concepts).topic_id[Optional ; Not repeatable ; String]
The identifier of the topic; this will often be a sequential number (Topic 1, Topic 2, etc.).topic_score[Optional ; Not repeatable ; Numeric]
The share of the topic in the metadata (%).topic_label[Optional ; Not repeatable ; String]
The label of the topic, if any (not automatically generated by the LDA model).topic_words[Optional ; Not repeatable]
The list of N keywords describing the topic (e.g., the top 5 words).
word[Optional ; Not repeatable ; String]
The word.word_weight[Optional ; Not repeatable ; Numeric]
The weight of the word in the definition of the topic.
embeddings[Optional ; Repeatable]
In Chapter 1 (section 1.n), we briefly introduced the concept of word embeddings and their use in implementation of semantic search tools. Word embedding models convert text (words, phrases, documents) into large-dimension numeric vectors (e.g., a vector of 100 or 200 numbers) that are representative of the semantic content of the text. The vectors are generated by submitting a text to a pre-trained word embedding model (possibly via an API).The word vectors do not have to be stored in the series/indicator metadata to be exploited by search engines. When a semantic search tool is implemented in a catalog, the vectors will be stored in a database end processed by a tool like Milvus. A metadata element is however provided to store the vectors for preservation and sharing purposes. This block of metadata elements is repeatable, allowing multiple vectors to be stored. When using vectors in a search engine, it is critical to only use vectors generated by one same model.
"embeddings": [
{
"id": "string",
"description": "string",
"date": "string",
"vector": null
}
]The embeddings element contains four metadata fields:
id[Optional ; Not repeatable ; String]
A unique identifier of the word embedding model used to generate the vector.description[Optional ; Not repeatable ; String]
A brief description of the model. This may include the identification of the producer, a description of the corpus on which the model was trained, the identification of the software and algorithm used to train the model, the size of the vector, etc.date[Optional ; Not repeatable ; String]
The date the model was trained (or a version date for the model).vector[Required ; Not repeatable ; @@@@] The numeric vector representing the video metadata.additional[Optional ; Not repeatable]
Theadditionalelement allows data curators to add their own metadata elements to the schema. All custom elements must be added within theadditionalblock; embedding them elsewhere in the schema would cause schema validation to fail.

11.3 Complete example
11.3.1 In R
library(nadar)
# ----------------------------------------------------------------------------------
# Enter credentials (API confidential key) and catalog URL
my_keys <- read.csv("C:/confidential/my_API_keys.csv", header=F, stringsAsFactors=F)
set_api_key("my_keys[1,1")
set_api_url("https://.../index.php/api/")
set_api_verbose(FALSE)
# ----------------------------------------------------------------------------------
setwd("C:/my_videos")
id = "MDA_VDO_001"
thumb = "vdo_001.jpg"
# Generate the metadata
my_video = list(
metadata_information = list(
title = "Mogadishu, Somalia: A Call for Help",
idno = id,
producers = list(
list(name = "John Doe", affiliation = "National Library")
),
production_date = "2021-09-03"
),
video_description = list(
idno = id,
title = "Mogadishu, Somalia: A Call for Help",
alt_title = "Somalia: Guterres in Mogadishu",
date_published = "2011-09-01",
description = "During a landmark visit, the United Nations High Commissioner for Refugees calls on the international community to rapidly increase aid to Somalia.",
genre = "Documentary",
persons = list(
list(name = "António Guterres", role = "High Commissioner for Refugees"),
list(name = "Fadhumo", role = "Somali internally displaced person (IDP)")
),
main_entity = "United Nations High Commission for Refugees (UNHCR), the UN Refugee Agency",
country = list(
list(name = "Somalia", code = "SOM")
),
spatial_coverage = "Mogadishu, Somalia",
content_reference_time = "2011-09",
languages = list(
list(name = "English", code = "EN")
),
creator = "United Nations High Commission for Refugees (UNHCR)",
video_url = "https://www.youtube.com/watch?v=7Aif1xjstws",
embed_url = "https://www.youtube.com/embed/7Aif1xjstws",
transcript = list(
list(
language = "English",
transcript = "Mogadishu is a dangerous place securityhas improved since al-shabaab militias
withdrew last month but not a lot despite the insecurity hundreds of thousands of Somalis
have been streaming into the capital from surrounding areas they're fleeing the worst famine
to strike the region in 60 years in a landmark visit the UN High Commissioner for Refugees
Antonio Gutierrez traveled to Mogadishu this week to visit with Somalis he urged the international
community to rapidly increase aid to people who have been through so much already makes us very emotional is to
feel that for 2020 as these people has been suffering the suffering enormously of course there is a large
responsibility of Somalis in the way things have happened but let's also recognize that international community
there sometimes also be part of the problem and not part of the solution some aid is getting through fatuma has
just been registered to receive assistance from UNHCR she left her home and is now seeking help in the capital
she is camped with thousands of others in a settlement not far from the shoreline UNHCR is providing plastic
sheeting and other supplies there are also food distributions there are a total of four hundred thousand displaced
people in Mogadishu 100,000 arrived in the past two months alone getting assistance to them despite the
dangers is an urgent priority otherwise settlements like these are certain to you"
)
),
duration = "PT2M14S" # 2 minutes and 14 seconds
)
)
# Publish in the NADA catalog
video_add(idno = id,
published = 1,
overwrite = "yes",
metadata = my_video,
thumbnail = thumb)In NADA, the video will now appear in the “All” tab and in the “Videos” tab.
If the embed_url element was provided, the video can be played within the NADA page.