Chapter 5 Microdata

5.1 Definition of microdata
When surveys or censuses are conducted, or when administrative data are recorded, information is collected on each unit of observation. The unit of observation can be a person, a household, a firm, an agricultural holding, a facility, or other. Microdata are the data files resulting from these data collection activities, which contain the unit-level information (as opposed to aggregated data in the form of counts, means, or other). Information on each unit is stored in variables, which can be of different types (e.g. numeric or alphanumeric, discrete or continuous). These variables may contain data reported by the respondent (e.g., the marital status of a person), obtained by observation or measurement (e.g., the GPS location of a dwelling), or generated by calculation, recoding or derivation (e.g., the sample weight in a survey).
For efficiency reasons, variables are often stored in numeric format (i.e. coded values), even when they contain qualitative information (coded values). For example, the sex of a respondent may be stored in a variable named ‘Q_01’, and include values 1, 2 and 9 where 1 represents “male”, 2 represents “female”, and 9 represents “unreported”. Microdata must therefore be provided at a minimum with a data dictionary containing the variables and value labels and, for derived variables, information of the derivation process. But many other features of a micro-dataset should also be described such as the objectives and the methodology of data collection (including a description of the sampling design for sample surveys), the period of data collection, the identification of the primary investigator and other contributors, the scope and geographic coverage of the data, and much more. This information will make the data usable and discoverable.
5.2 The Data Documentation Initiative (DDI) metadata standard
The DDI metadata standard provides a structured and comprehensive list of hundreds of elements and attributes which may be used to document microdata. It is unlikely that any one study would ever require using them all, but this list provides a convenient solution to foster completeness of the information, and to generate documentation that will meet the needs of users.
The Data Documentation Initiative (DDI) metadata standard originated in the Inter-university Consortium for Political and Social Research (ICPSR), a membership-based organization with more than 500 member colleges and universities worldwide. The DDI is now the project of an alliance of North American and European institutions. Member institutions comprise many of the largest data producers and data archives in the world. The DDI standard is used by a large community of data archivists, including data librarians from academia, data managers in national statistical agencies and other official data producing agencies, and international organizations. The standard has two branches: the DDI-Codebook (version 2.x) and the DDI LifeCycle (version 3.x). These two branches serve different purposes and audiences. For the purpose of data archiving and cataloguing, the schema we recommend in this Guide is the DDI-Codebook. We use a slightly simplified version of version 2.5 of the standard, to which we add a few elements (including the tags element common to all schemas described in the Guide. A mapping between the elements included in our schema and the DDI Codebook metadata tags is provided in annex 2.
The DDI standard is published under the terms of the [GNU General Public License]((http://www.gnu.org/licenses) (version 3 or later).
5.2.1 DDI-Codebook
The DDI Alliance developed the DDI-Codebook for organizing the content, presentation, transfer, and preservation of metadata in the social and behavioral sciences. It enables documenting microdata files in a simultaneously flexible and rigorous way. The DDI-Codebook aims to provide a straightforward means of recording and communicating all the salient characteristics of a micro-dataset.
The DDI-Codebook is designed to encompass the kinds of data resulting from surveys, censuses, administrative records, experiments, direct observation and other systematic methodology for generating empirical measurements. The unit of observation can be individual persons, households, families, business establishments, transactions, countries or other subjects of scientific interest.
The DDI Alliance publishes the DDI-Codebook as an XML schema. We present in this Guide a JSON implementation of the schema, which is used in our R package NADAR and Python Library PyNADA. The NADA cataloguing application works with both the XML and the JSON version. A DDI-compliant metadata file can be converted from the JSON schema to the XML or from XML to JSON.
5.2.2 DDI-Lifecycle
As indicated by the DDI Alliance website, DDI-Lifecycle is “designed to document and manage data across the entire life cycle, from conceptualization to data publication, analysis and beyond. It encompasses all of the DDI-Codebook specification and extends it. Based on XML Schemas, DDI-Lifecycle is modular and extensible.” DDI-lifecycle can be used to “populate variable and question banks to explore available data and question structures for reuse in new surveys”. As this is not our objective, and because using the DDI-Lifecycle adds significant complexity, we do not make use of it and this chapter only covers the DDI-Codebook.
5.3 Some practical considerations
The DDI is a comprehensive schema that provides metadata elements to document a study (e.g., a survey, or an administrative datasets), the related data files, and the variables they contain. A separate schema is used to document the related resources (questionnaires, reports, and others); see Chapter 13.
Some datasets may contain hundreds or even thousands of variables. For each variable, the DDI can include not only the variable name, label and description, but also summary statistics like the count of valid and missing observations, weighted and unweighted frequencies, means, and others. Generating a DDI file manually, in particular the variable-level metadata, can be a tedious and time consuming task. But variable names, summary statistics, and (when avaiulable) variable and value labels can be extracted directly from the data files. User-friendly solutions (specialized metadata editors) are available to automate a large part of this work. DDI can also be generated programmatically using R or Python. Section 5.5 provides examples of the use of specialized DDI metadata editors and programming languages to generate DDI-compliant metadata.
Documenting microdata is more complex than documenting publications or other types of data like tables or indicators. The production of microdata often involves experts in survey design, sampling, data processing, and analysis. Generating the metadata should thus be a collective responsibility and will ideally be done in real time (“document as you survey”). Data documentation should be implemented during the whole lifecycle of data production, not as an ex post task. This is in line with what the Generic Statistical Business process Model (GSBPM) recommends: “Good metadata management is essential for the efficient operation of statistical business processes. Metadata are present in every phase, either created, updated or carried forward from a previous phase or reused from another business process. In the context of this model, the emphasis of the overarching process of metadata management is on the creation/revision, updating, use and archiving of statistical metadata, though metadata on the different sub-processes themselves are also of interest, including as an input for quality management. The key challenge is to ensure that these metadata are captured as early as possible, and stored and transferred from phase to phase alongside the data they refer to.” Too often, microdata are documented after completion of the data collection, sometimes by a team who was not directly involved in the production of the data. In such cases, some information may not have been captured and will be difficult to find or reconstruct.
Suggestions and recommendations to data curators
- Generating detailed metadata at the variable level (including elements like the formulation of the questions, variable and value labels, interviewer instructions, universe, derivation procedures, etc.) may seem to be a tedious exercise, but it adds considerable value to the metadata. Indeed, it will (i) provide a detailed data dictionary, required to make the data usable, (ii) provide the necessary information for making the data more discoverable and to enable variable comparison tools, and (iii) guarantee the preservation of institutional memory. The cost of generating such metadata will be very small relative to the cost of generating the data.
- To make the data more discoverable, attention should be paid to provide a detailed description of the scope and objectives of the data collection. When a survey (or other microdataset) is used to generate statistical indicators, a list of these indicators should be provided in the metadata.
- The
keywordsmetadata element provides a flexible solution to improve the discoverability of data. For example, a survey that collects data on children age, weight and height, will be relevant for measuring malnutrition and generating indicators like prevalence of stunting or wasting, overweight and underweight. The variable description alone would not make the data discoverable in keyword-based search engines, hence the importance of adding relevant terms and phrases in thekeywordsection. - The DDI metadata will be saved as an XML or JSON file, i.e. as plain text. This means that the DDI metadata cannot include complex formulas. The description of some variables, as well as the description of a survey sample design, may require the use of formulas. In such case, the recommendation is to provide as much of the information as possible in the DDI, and to provide links to documents where the formulas can be found (these documents would be published with the metadata as external resources).
- Typically, the variables in the DDI are organized by data file. The DDI provides an option –the
variable groups– to organize variables differently, for example thematically. These variable groupings are virtual, in the sense that they do not impact the way variables are stored. Not all variables have to be mapped to such groups, and a same variable can belong to more than one group. This option provides the possibility to organize the variables based on a thematic or topical classification. Machine learning (AI) tools make it possible to automate the process of mapping variables to a pre-defined list of groups (each one of them described by a label and a short description). By doing this, and by generating embeddings at the group level, it becomes possible to add semantic search and to implement a recommender system that applies to microdata.
5.4 Schema description: DDI-Codebook 2.5
The DDI-Codebook is a comprehensive, structured list of elements to be used to document microdata of any source. The standard contains five main sections:
- Document description (
doc_desc), with elements used to describe the metadata (not the data); the term “document” refers here to the XML (or JSON) file that contains the metadata. - Study description (
study_desc), which contains the elements used to describe the study itself (the survey, the administrative process, or the other activity that resulted in the production of the microdata). This section will contain information on the primary investigator, scope and coverage of the data, sampling, etc. - File description (
data_files), which provides elements to document each data file that compose the dataset (this is thus a repeatable block of elements). - Variable description (
variables), with elements used to describe each variable contained in the data files, including the variable names, the variable and value labels, summary statistics for each variable, interviewers’ instructions, description of recoding or derivation procedure, and more. - Variable groups (
variable_groups), an optional section that allows organizing variables by thematic or other groups, independently from the data file they belong to. Variable groups are “virtual”; the grouping of variables does not affect the data files.
The other sections in the schema are not part of the DDI Codebook itself. Some are used for catalog administration purposes when the NADA cataloguing application is used (repositoryid, access_policy, published, overwrite, and provenance).
repositoryididentifies the data catalog/collection in which the metadata will be published.access_policyindicates the access policy to be applied to the microdata (open access, public use files, licensed access, no access, etc.)published: Indicates whether the metadata will be made visible to visitors of the catalog. By default, the value is 0 (unpublished). This value must be set to 1 (published) to make the metadata visible.overwrite: Indicates whether metadata that may have been previously uploaded for the same dataset can be overwritten. By default, the value is “no”. It must be set to “yes” to overwrite existing information. Note that a dataset will be considered as being the same as a previously uploaded one if the identifier provided in the metadata elementstudy_desc > title_statement > idnois the same.provenanceis used to store information on the source and time of harvesting, for metadata that were extracted automatically from external data catalogs.
Other sections are provided to allow additional metadata to be collected and stored, including metadata generated by machine learning models (tags, lda_topics, embeddings, and additional). The tags is a section common to all schemas (with the exception of the external resources schema), which provides a flexible solution to generate customized facets in data catalogs. The additional section allows data curators to supplement the DDI standard with their own metadata elements, without breaking compliance with the DDI.
{
"repositoryid": "string",
"access_policy": "data_na",
"published": 0,
"overwrite": "no",
"doc_desc": {},
"study_desc": {},
"data_files": [],
"variables": [],
"variable_groups": [],
"provenance": [],
"tags": [],
"lda_topics": [],
"embeddings": [],
"additional": { }
}The DDI-Codebook also provides a solution to describe OLAP cubes, which we do not make use of as our purpose is to use the standard to document and catalog datasets, not to manage data.
Each metadata element in the DDI standard has a name. In our JSON version of the standard, we do not make use of the exact same names. We adapted some of them for clarity. For example, we renamed the DDI element titlStmt as title_statement. The mapping between the DDI Codebook 2.5 standard and the elements in our schema is provided in appendix. JSON files created using our adapted version of the DDI can be exported as a DDI 2.5 compliant and validated XML file using R or Python scripts provided in the NADAR package and PyNADA library.
5.4.1 Document description
doc_desc [Optional ; Not repeatable]
Documenting a study using the DDI-Codebook standard consists of generating a metadata file in XML or JSON format. This file is what is referred to as the metadata document. The doc_desc or document description is thus a description of the metadata file, and consists of bibliographic information describing the DDI-compliant document as a whole. As a same dataset can possibly be documented by more than one organization, and because metadata can be automatically harvested by on-line catalogs, traceability of the metadata is important. This section, which only contains five main elements, should be as complete as possible, and at least contain information on the producer and prod_date; information.
"doc_desc": {
"title": "string",
"idno": "string",
"producers": [
{
"name": "string",
"abbr": "string",
"affiliation": "string",
"role": "string"
}
],
"prod_date": "string",
"version_statement": {
"version": "string",
"version_date": "string",
"version_resp": "string",
"version_notes": "string"
}
}title[Optional ; Not repeatable ; String]
The title of the metadata document (which may be the title of the study itself). The metadata document is the DDI metadata file (XML or JSON file) that is being generated. The “Document title” should mention the geographic scope of the data collection as well as the time period covered. For example: “DDI 2.5: Albania Living Standards Study 2012”.idno[Optional ; Not repeatable ; String]
A unique identifier for the metadata document. This identifier must be unique in the catalog where the metadata are intended to be published. Ideally, the identifier should also be unique globally. This is different from the unique identifieridnofound in sectionstudy_description / title_statement, although it is good practice to generate identifiers that establish a clear connection between the two identifiers. The Document ID could also include the metadata document version identifier. For example, if the “Primary identifier” of the study is “ALB_LSMS_2012”, the “Document ID” in the Metadata information could be “IHSN_DDI_v01_ALB_LSMS_2012” if the DDI metadata are produced by the IHSN. Each organization should establish systematic rules to generate such IDs. A validation rule can be set (using a regular expression) in user templates to enforce a specific ID format. The identifier should not contain blank spaces.producers[Optional ; Repeatable]
The metadata producer is the person or organization with the financial and/or administrative responsibility for the processes whereby the metadata document was created. This is a “Recommended” element. For catalog administration purposes, information on the producer and on the date of metadata production is useful.name[Optional ; Not repeatable ; String]
The name of the person or organization in charge of the production of the DDI metadata. If the name of individuals cannot be provided due to an organization’s data protection rules, the title of the person, or an anonymized identifier, can be provided (or this field can be left blank if no other option is available).abbr[Optional ; Not repeatable ; String]
The initials of the person, or the abbreviation of the organization’s name mentioned inname.affiliation[Optional ; Not repeatable ; String]
The affiliation of the person or organization mentioned inname.role[Optional ; Not repeatable ; String]
The specific role of the person or organization mentioned innamein the production of the DDI metadata.
prod_date[Optional ; Not repeatable ; String]
The date the DDI metadata document was produced (not the date it was distributed or archived), preferably entered in ISO 8601 format (YYYY-MM-DD or YYY-MM). This is a “Recommended” element, as information on the producer and on the date of metadata production is useful for catalog administration purposes.version_statement[Optional ; Not repeatable]
A version statement for the metadata (DDI) document. Documenting a dataset is not a trivial exercise. It may happen that, having identified errors or gaps in a DDI document, or after receiving suggestions for improvement or additional input, the DDI metadata are modified. Theversion_statementdescribes the version of the metadata document. It is good practice to provide a version number and date, and information on what distinguishes the current version from the previous one(s).version[Optional ; Not repeatable ; String]
The label of the version, also known as release or edition. For example, Version 1.2version_date[Optional ; Not repeatable ; String]
The date when this version of the metadata document (DDI file) was produced, preferably identifying an exact date. This will usually correspond to theprod_dateelement. It is recommended to enter the date in the ISO 8601 date format (YYYY-MM-DD or YYYY-MM or YYYY).version_resp[Optional ; Not repeatable ; String]
The organization or person responsible for this version of the metadata document.version_notes[Optional ; Not repeatable ; String]
This element can be used to clarify information/annotation regarding this version of the metadata document, for example to indicate what is new or specific in this version comparing with a previous version.
my_ddi <- list(
doc_desc = list(
title = "Albania Living Standards Study 2012",
idno = "DDI_WB_ALB_2012_LSMS_v02",
producers = list(
list(name = "Development Data Group",
abbr = "DECDG",
affiliation = "World Bank",
role = "Production of the DDI-compliant metadata"
)
),
prod_date = "2021-02-16",
version_statement = list(
version = "Version 2.0",
version_date = "2021-02-16",
version_resp = "OD",
version_notes = "Version identical to Version 1.0 except for the Data Appraisal section which was added."
)
),
# ... (other sections of the DDI)
) 5.4.2 Study description
study_desc [Required ; Not repeatable]
The study_desc or study description consists of information about the data collection or study that the DDI-compliant documentation file describes. This section includes study-level information such as scope and coverage, objectives, producers, sampling, data collection dates and methods, etc.
"study_desc": {
"title_statement": {},
"authoring_entity": [],
"oth_id": [],
"production_statement": {},
"distribution_statement": {},
"series_statement": {},
"version_statement": {},
"bib_citation": "string",
"bib_citation_format": "string",
"holdings": [],
"study_notes": "string",
"study_authorization": {},
"study_info": {},
"study_development": {},
"method": {},
"data_access": {}
}5.4.2.1 Title statement
title_statement [Required ; Not repeatable]
The title statement for the study.
"title_statement": {
"idno": "string",
"identifiers": [
{
"type": "string",
"identifier": "string"
}
],
"title": "string",
"sub_title": "string",
"alternate_title": "string",
"translated_title": "string"
}idno[Required ; Not repeatable ; String]
idnois the primary identifier of the dataset. It is a unique identification number used to identify the study (survey, census or other). A unique identifier is required for cataloguing purpose, so this element is declared as “Required”. The identifier will allow users to cite the dataset properly. The identifier must be unique within the catalog. Ideally, it should also be globally unique; the recommended option is to obtain a Digital Object Identifier (DOI) for the study. Alternatively, theidnocan be constructed by an organization using a consistent scheme. The scheme could for example be “catalog-country-study-year-version”, where country is the 3-letter ISO country code, producer is the abbreviation of the producing agency, study is the study acronym, year is the reference year (or the year the study started), version is a version number. Using that scheme, the Uganda 2005 Demographic and Health Survey for example would have the followingidno(where “MDA” stand for “My Data Archive”): MDA_UGA_DHS_2005_v01. Note that the schema allows you to provide more than one identifier for a same study (in elementidentifiers); a catalog-specific identifier is thus not incompatible with a globally unique identifier like a DOI. The identifier should not contain blank spaces.identifiers[Optional ; Repeatable]
This repeatable element is used to enter identifiers (IDs) other than theidnoentered in the Title statement. It can for example be a Digital Object Identifier (DOI). Theidnocan be repeated here (theidnoelement does not provide atypeparameter; if a DOI or other standard reference ID is used asidno, it is recommended to repeat it here with the identification of itstype).type[Optional ; Not repeatable ; String]
The type of unique ID, e.g. “DOI”.identifier[Required ; Not repeatable ; String]
The identifier itself.
title[Required ; Not repeatable ; String]
This element is “Required”. Provide here the full authoritative title for the study. Make sure to use a unique name for each distinct study. The title should indicate the time period covered. For example, in a country conducting monthly labor force surveys, the title of a study would be like “Labor Force Survey, December 2020”. When a survey spans two years (for example, a household income and expenditure survey conducted over a period of 12 months from June 2020 to June 2021), the range of years can be provided in the title, for example “Household Income and Expenditure Survey 2020-2021”. The title of a survey should be its official name as stated on the survey questionnaire or in other study documents (report, etc.). Including the country name in the title is optional (another metadata element is used to identify the reference countries). Pay attention to the consistent use of capitalization in the title.sub_title[Optional ; Not repeatable ; String]
Thesub-titleis a secondary title used to amplify or state certain limitations on the main title, for example to add information usually associated with a sequential qualifier for a survey. For example, we may have “[country] Universal Primary Education Project, Impact Evaluation Survey 2007” astitle, and “Baseline dataset” assub-title. Note that this information could also be entered as a Title with no Subtitle: “[country] Universal Primary Education Project, Impact Evaluation Survey 2007 - Baseline dataset”.alternate_title[Optional ; Not repeatable ; String]
Thealternate_titlewill typically be used to capture the abbreviation of the survey title. Many surveys are known and referred to by their acronym. The survey reference year(s) may be included. For example, the “Demographic and Health Survey 2012” would be abbreviated as “DHS 2012”, or the “Living Standards Measurement Study 2020-2012” as “LSMS 2020-2021”.translated_title[Optional ; Not repeatable ; String]
In countries with more than one official language, a translation of the title may be provided here. Likewise, the translated title may simply be a translation into English from a country’s own language. Special characters should be properly displayed, such as accents and other stress marks or different alphabets.
my_ddi <- list(
# ... ,
study_desc = list(
title_statement = list(
idno = "ML_ALB_2012_LSMS_v02",
identifiers = list(
list(type = "DOI", identifier = "XXX-XXXX-XXX")
),
title = "Living Standards Study 2012",
alternate_title = "LSMS 2012",
translated_title = "Anketa e Matjes së Nivelit të Jetesës (AMNJ) 2012"
)
),
# ...
) 5.4.2.3 Other entity
oth_id [Optional ; Repeatable]
This element is used to acknowledge any other people and organizations that have in some form contributed to the study. This does not include other producers which should be listed in producers, and financial sponsors which should be listed in the element funding_agencies.
"oth_id": [
{
"name": "string",
"role": "string",
"affiliation": "string"
}
]name[Required ; Not repeatable ; String]
The name of the person or organization.role[Optional ; Not repeatable ; String]
A brief description of the specific role of the person or organization mentioned inname.affiliation[Optional ; Not repeatable ; String]
The affiliation of the person or organization mentioned inname.
my_ddi <- list(
# ... ,
study_desc = list(
# ... ,
oth_id = list(
list(name = "John Doe",
role = "Technical advisor in sample design",
affiliation = "World Bank Group"
)
),
# ...
)
) 5.4.2.4 Production statement
production_statement [Optional ; Not repeatable]
A production statement for the work at the appropriate level.
"production_statement": {
"producers": [
{
"name": "string",
"abbr": "string",
"affiliation": "string",
"role": "string"
}
],
"copyright": "string",
"prod_date": "string",
"prod_place": "string",
"funding_agencies": [
{
"name": "string",
"abbr": "string",
"grant": "string",
"role": "string"
}
]
}producers[Optional ; Repeatable]
This field is provided to list other interested parties and persons that have played a significant but not the leading technical role in implementing and producing the data (which will be listed inauthoring_entity), and not the financial sponsors (which will be listed infunding_agencies).name[Required ; Not repeatable ; String]
The name of the person or organization.abbr[Optional ; Not repeatable ; String]
The official abbreviation of the organization mentioned inname.affiliation[Optional ; Not repeatable ; String]
The affiliation of the person or organization mentioned inname.role[Optional ; Not repeatable ; String]
A succinct description of the specific contribution by the person or organization in the production of the data.
copyright[Optional ; Not repeatable ; String]
A copyright statement for the study at the appropriate level.prod_date[Optional ; Not repeatable ; String]
This is the date (preferably entered in ISO 8601 format: YYYY-MM-DD or YYYY-MM or YYYY) of the actual and final production of the version of the dataset being documented. At least the month and year should be provided. A regular expression can be entered in user templates to validate the information captured in this field.prod_place[Optional ; Not repeatable ; String]
The address of the organization that produced the study.funding_agencies[Optional ; repeatable]
The source(s) of funds for the production of the study. If different funding agencies sponsored different stages of the production process, use theroleattribute to distinguish them.name[Required ; Not repeatable ; String]
The name of the funding agency.abbr[Optional ; Not repeatable ; String]
The abbreviation (acronym) of the funding agency mentioned inname.grant[Optional ; Not repeatable ; String]
The grant number. If an agency has provided more than one grant, list them all separated with a “;”.role[Optional ; Not repeatable ; String]
The specific contribution of the funding agency mentioned inname. This element is used when multiple funding agencies are listed to distinguish their specific contributions.
This example shows the Bangladesh 2018-2019 Demographic and Health Survey (DHS)
my_ddi <- list(
# ... ,
study_desc = list(
# ... ,
production_statement = list(
producers = list(
list(name = "National Institute of Population Research and Training",
abbr = "NIPORT",
role = "Primary investigator"),
list(name = "Medical Education and Family Welfare Division",
role = "Advisory"),
list(name = "Ministry of Health and Family Welfare",
abbr = "MOHFW",
role = "Advisory"),
list(name = "Mitra and Associates",
role = "Data collection - fieldwork"),
list(name = "ICF (consulting firm)",
role = "Technical assistance / DHS Program")
),
prod_date = "2019",
prod_place = "Dhaka, Bangladesh",
funding_agencies = list(
list(name = "United States Agency for International Development",
abbr = "USAID")
)
),
# ...,
)
# ...
)5.4.2.5 Distribution statement
distribution_statement [Optional ; Not repeatable]
A distribution statement for the study.
"distribution_statement": {
"distributors": [
{
"name": "string",
"abbr": "string",
"affiliation": "string",
"uri": "string"
}
],
"contact": [
{
"name": "string",
"affiliation": "string",
"email": "string",
"uri": "string"
}
],
"depositor": [
{
"name": "string",
"abbr": "string",
"affiliation": "string",
"uri": "string"
}
],
"deposit_date": "string",
"distribution_date": "string"
}distributors[Optional ; Repeatable]
The organization(s) designated by the author or producer to generate copies of the study output including any necessary editions or revisions.name[Required ; Not repeatable ; String]
The name of the distributor. It can be an individual or an organization.abbr[Optional ; Not repeatable ; String]
The official abbreviation of the organization mentioned inname.affiliation[Optional ; Not repeatable ; String]
The affiliation of the person or organization mentioned inname.uri[Optional ; Not repeatable ; String]
A URL to the ordering service or download facility on a Web site.
contact[Optional ; Repeatable]
Names and addresses of individuals responsible for the study. Individuals listed as contact persons will be used as resource persons regarding problems or questions raised by users.name[Required ; Not repeatable ; String]
The name of the person or organization that can be contacted.affiliation[Optional ; Not repeatable ; String]
The affiliation of the person or organization mentioned inname.email[Optional ; Not repeatable ; String]
An email address for the contact mentioned inname.uri[Optional ; Not repeatable ; String]
A URL to the contact mentioned inname.
depositor[Optional ; Repeatable]
The name of the person (or institution) who provided this study to the archive storing it.name[Required ; Not repeatable ; String]
The name of the depositor. It can be an individual or an organization.abbr[Optional ; Not repeatable ; String]
The official abbreviation of the organization mentioned inname.affiliation[Optional ; Not repeatable ; String]
The affiliation of the person or organization mentioned inname.uri[Optional ; Not repeatable ; String]
A URL to the depositor
deposit_date[Optional ; Not repeatable ; String]
The date that the study was deposited with the archive that originally received it. The date should be entered in the ISO 8601 format (YYYY-MM-DD or YYYY-MM or YYYY). The exact date should be provided when possible.distribution_date[Optional ; Not repeatable ; String]
The date that the study was made available for distribution/presentation. The date should be entered in the ISO 8601 format (YYYY-MM-DD or YYYY-MM or YYYY). The exact date should be provided when possible.
This example is @@@@@@@@@@@@
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
distribution_statement = list(
distributors = list(
list(name = "World Bank Microdata Library",
abbr = "WBML",
affiliation = "World Bank Group",
uri = "http:/microdata.worldbank.org")
),
contact = list(
list(name = "",
affiliation = "",
email = "",
uri = "")
),
depositor = list(
list(name = "",
abbr = "",
affiliation = "",
uri = "")
),
deposit_date = "",
distribution_date = ""
),
# ...
)
# ...
) 5.4.2.6 Series statement
series_statement [Optional; Not repeatable]
A study may be repeated at regular intervals (such as an annual labor force survey), or be part of an international survey program (such as the MICS, DHS, LSMS and others). The series statement provides information on the series.
"series_statement": {
"series_name": "string",
"series_info": "string"
}series_name[Optional ; Not repeatable ; String]
The name of the series to which the study belongs. For example, “Living Standards Measurement Study (LSMS)” or “Demographic and Health Survey (DHS)” or “Multiple Indicator Cluster Survey VII (MICS7)”. A description of the series can be provided in the element “series_info”.series_info[Optional ; Not repeatable ; String]
A brief description of the characteristics of the series, including when it started, how many rounds were already implemented, and who is in charge would be provided here.
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
series_statement = list(
list(series_name = "Multiple Indicator Cluster Survey (MICS) by UNICEF",
series_info = "The Multiple Indicator Cluster Survey, Round 3 (MICS3) is the third round of MICS surveys, previously conducted around 1995 (MICS1) and 2000 (MICS2). MICS surveys are designed by UNICEF, and implemented by national agencies in participating countries. MICS was designed to monitor various indicators identified at the World Summit for Children and the Millennium Development Goals. Many questions and indicators in MICS3 are consistent and compatible with the prior round of MICS (MICS2) but less so with MICS1, although there have been a number of changes in definition of indicators between rounds. Round 1 covered X countries, round 2 covered Y countries, and Round 3 covered Z countries.")
),
# ...
),
# ...
) 5.4.2.7 Version statement
version_statement [Optional; Not repeatable]
Version statement for the study.
"version_statement": {
"version": "string",
"version_date": "string",
"version_resp": "string",
"version_notes": "string"
}The version statement should contain a version number followed by a version label. The version number should follow a standard convention to be adopted by the data repository. We recommend that larger series be defined by a number to the left of a decimal and iterations of the same series by a sequential number that identifies the release. The left number could for example be (0) for the raw, unedited dataset; (1) for the edited dataset, non anonymized, available for internal use at the data producing agency; and (2) the edited dataset, prepared for dissemination to secondary users (possibly anonymized). Example:
v0: Basic raw data, resulting from the data capture process, before any data editing is implemented.
v1.0: Edited data, first iteration, for internal use only.
v1.1: Edited data, second iteration, for internal use only.
v2.1: Edited data, anonymized and packaged for public distribution.
version[Optional ; Not repeatable ; String]
The version number, also known as release or edition.version_date[Optional ; Not repeatable ; String]
The ISO 8601 standard for dates (YYYY-MM-DD) is recommended for use with the “date” attribute.version_resp[Optional ; Not repeatable ; String]
The person(s) or organization(s) responsible for this version of the study.version_notes[Optional ; Not repeatable ; String]
Version notes should provide a brief report on the changes made through the versioning process. The note should indicate how this version differs from other versions of the same dataset.
my_ddi <- list(
# ...
study_desc = list(
# ... ,
version_statement = list(
version = "Version 1.1",
version_date = "2021-02-09",
version_resp = "National Statistics Office, Data Processing unit",
version_notes = "This dataset contains the edited version of the data that were used to produce the Final Survey Report. It is equivalent to version 1.0 of the dataset, except for the addition of an additional variable (variable weight2) containing a calibrated version of the original sample weights (variable weight)"
),
# ...
),
# ...
) 5.4.2.8 Bibliographic citation
bib_citation [Optional ; Not repeatable ; String]
Complete bibliographic reference containing all of the standard elements of a citation that can be used to cite the study. The bib_citation_format (see below) is provided to enable specification of the particular citation style used, e.g., APA, MLA, or Chicago.
5.4.2.9 Bibliographic citation format
bib_citation_format [Optional ; Not repeatable ; String]
This element is used to specify the particular citation style used in the field bib_citation described above, e.g., APA, MLA, or Chicago.
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
bib_citation = "",
bib_citation_format = ""
# ...
),
# ...
) 5.4.2.10 Holdings
holdings [Optional ; Repeatable]
Information concerning either the physical or electronic holdings of the study being described.
"holdings": [
{
"name": "string",
"location": "string",
"callno": "string",
"uri": "string"
}
]name[Optional ; Not repeatable ; String]
Name of the physical or electronic holdings of the cited study.location[Optional ; Not repeatable ; String]
The physical location where a copy of the study is held.callno[Optional ; Not repeatable ; String]
The call number at the location specified inlocation.uri[Optional ; Not repeatable ; String]
A URL for accessing the electronic copy of the cited study from the location mentioned inname.
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
holdings = list(
name = "World Bank Microdata Library",
location = "World Bank, Development Data Group",
uri = "http://microdata.worldbank.org"
),
# ...
),
# ...
) 5.4.2.11 Study notes
study_notes [Optional ; Not repeatable]
This element can be used to provide additional information on the study which cannot be accommodated in the specific metadata elements of the schema, in the form of a free text field.
5.4.2.12 Study autorization
study_authorization [Optional ; Not repeatable]
"study_authorization": {
"date": "string",
"agency": [
{
"name": "string",
"affiliation": "string",
"abbr": "string"
}
],
"authorization_statement": "string"
}Provides structured information on the agency that authorized the study, the date of authorization, and an authorization statement. This element will be used when a special legislation is required to conduct the data collection (for example a Census Act) or when the approval of an Ethics Board or other body is required to collect the data.
date[Optional ; Not repeatable ; String] The date, preferably entered in ISO 8601 format (YYYY-MM-DD), when the authorization to conduct the study was granted.agency[Optional ; Repeatable]
Identification of the agency that authorized the study.name[Optional ; Not repeatable ; String]
Name of the agent or agency that authorized the study.affiliation[Optional ; Not repeatable ; String]
The institutional affiliation of the authorizing agent or agency mentioned inname.abbr[Optional ; Not repeatable ; String]
The abbreviation of the authorizing agent’s or agency’s name.
authorization_statement[Optional ; Not repeatable ; String]
The text of the authorization (or a description and link to a document or other resource containing the authorization statement).
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
study_authorization = list(
date = "2018-02-23",
agency = list(
name = "Institutional Review Board of the University of Popstan",
abbr = "IRB-UP")
),
authorization_statement = "The required documentation covering the study purpose, disclosure information, questionnaire content, and consent statements was delivered to the IRB-UP on 2017-12-27 and was reviewed by the compliance officer. Statement of authorization for the described study was issued on 2018-02-23."
# ...
),
# ...
) 5.4.2.13 Study information
study_info [Required ; Not repeatable]
This section contains the metadata elements needed to describe the core elements of a study including the dates of data collection and reference period, the country and other geographic coverage information, and more. These elements are not required in the DDI standard, but documenting a study without provinding at least some of this information would make the metadata mostly irrelevant.
"study_info": {
"study_budget": "string",
"keywords": [],
"topics": [],
"abstract": "string",
"time_periods": [],
"coll_dates": [],
"nation": [],
"bbox": [],
"bound_poly": [],
"geog_coverage": "string",
"geog_coverage_notes": "string",
"geog_unit": "string",
"analysis_unit": "string",
"universe": "string",
"data_kind": "string",
"notes": "string",
"quality_statement": {},
"ex_post_evaluation": {}
}study_budget[Optional ; Not repeatable ; String]This is a free-text field, not a structured element. The budget of a study will ideally be described by budget line. The currency used to describe the budget should be specified. This element can also be used to document issues related to the budget (e.g., documenting possible under-run and over-run).
my_ddi <- list( # ... , study_desc = list( # ... , study_info = list( study_budget = "The study had a total budget of 500,000 USD allocated as follows: By type of expense: - Staff: 150,000 USD - Consultants (incl. interviewers): 180,000 USD - Travel: 50,000 USD - Equipment: 90,000 USD - Other: 30,000 USD By activity - Study design (questionnaire design and testing, sampling, piloting): 100,000 USD - Data collection: 250,000 USD - Data processing and tabulation: 80,000 USD - Analysis and dissemination: 50,000 USD - Evaluation: 20,000 USD By source of funding: - Government budget: 300,000 USD - External sponsors - Grant ABC001 - 150,000 USD - Grant XYZ987 - 50,000 USD", # ... ), # ... )keywords[Optional ; Repeatable]
"keywords": [
{
"keyword": "string",
"vocab": "string",
"uri": "string"
}
]Keywords are words or phrases that describe salient aspects of a data collection’s content. The addition of keywords can significantly improve the discoverability of data. Keywords can summarize and improve the description of the content or subject matter of a study. For example, keywords “poverty”, “inequality”, “welfare”, and “prosperity” could be attached to a household income survey used to generate poverty and inequality indicators (for which these keywords may not appear anywhere else in the metadata). A controlled vocabulary can be employed. Keywords can be selected from a standard thesaurus, preferably an international, multilingual thesaurus.
- keyword [ Required ; String ; Non repeatable]
A keyword (or phrase).
- vocab [Optional ; Not repeatable ; String]
The controlled vocabulary from which the keyword is extracted, if any.
- uri [Optional ; Not repeatable ; String]
The URI of the controlled vocabulary used, if any.
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
study_info = list(
# ... ,
keywords = list(
list(keyword = "poverty",
vocab = "UNESCO Thesaurus",
uri = "http://vocabularies.unesco.org/browser/thesaurus/en/"),
list(keyword = "income distribution",
vocab = "UNESCO Thesaurus",
uri = "http://vocabularies.unesco.org/browser/thesaurus/en/"),
list(keyword = "inequality",
vocab = "UNESCO Thesaurus",
uri = "http://vocabularies.unesco.org/browser/thesaurus/en/")
),
# ...
),
# ...
) topics[Optional ; Repeatable]
Thetopicsfield indicates the broad substantive topic(s) that the study covers. A topic classification facilitates referencing and searches in on-line data catalogs.
"topics": [
{
"topic": "string",
"vocab": "string",
"uri": "string"
}
]topic[Required ; Not repeatable]
The label of the topic. Topics should be selected from a standard controlled vocabulary such as the Council of European Social Science Data Archives (CESSDA) Topic Classification.vocab[Required ; Not repeatable]
The specification (name including the version) of the controlled vocabulary in use.uri[Required ; Not repeatable]
A link (URL) to the controlled vocabulary website.
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
study_info = list(
# ... ,
topics = list(
list(topic = "Equality, inequality and social exclusion",
vocab = "CESSDA topics classification",
uri = "https://vocabularies.cessda.eu/vocabulary/TopicClassification"),
list(topic = "Social and occupational mobility",
vocab = "CESSDA topics classification",
uri = "https://vocabularies.cessda.eu/vocabulary/TopicClassification")
),
# ...
),
# ...
) abstract[Optional ; Not repeatable ; String]
An un-formatted summary describing the purpose, nature, and scope of the data collection, special characteristics of its contents, major subject areas covered, and what questions the primary investigator(s) attempted to answer when they conducted the study. The summary should ideally be between 50 and 5000 characters long. The abstract should provide a clear summary of the purposes, objectives and content of the survey. It should be written by a researcher or survey statistician aware of the study. Inclusion of this element is strongly recommended.This example is for the Afrobarometer Survey 1999-2000, Merged Round 1 dataset.
my_ddi <- list( doc_desc = list( # ... ), study_desc = list( # ... , study_info = list( # ... , abstract = "The Afrobarometer is a comparative series of public attitude surveys that assess African citizen's attitudes to democracy and governance, markets, and civil society, among other topics. The 12 country dataset is a combined dataset for the 12 African countries surveyed during round 1 of the survey, conducted between 1999-2000 (Botswana, Ghana, Lesotho, Mali, Malawi, Namibia, Nigeria South Africa, Tanzania, Uganda, Zambia and Zimbabwe), plus data from the old Southern African Democracy Barometer, and similar surveys done in West and East Africa.", # ... ), # ... )time_periods[Optional ; Repeatable]
This refers to the time period (also known as span) covered by the data, not the dates of data collection.
"time_periods": [
{
"start": "string",
"end": "string",
"cycle": "string"
}
]start[Required ; Not repeatable ; String]
The start date for the cycle being described. Enter the date in ISO 8601 format (YYYY-MM-DD or YYYY-MM or YYYY).end[Required ; Not repeatable ; String]
The end date for the cycle being described. Enter the date in ISO 8601 format (YYYY-MM-DD or YYYY-MM or YYYY). Indicate open-ended dates with two decimal points (..)cycle[Optional ; Not repeatable ; String]
Thecycleattribute permits specification of the relevant cycle, wave, or round of data.coll_dates[Optional ; Repeatable]
Contains the date(s) when the data were collected, which may be different from the date the data refer to (seetime_periodsabove). For example, data may be collected over a period of 2 weeks (coll_dates) about household expenditures during a reference week (time_periods) preceding the beginning of data collection. Use the event attribute to specify the “start” and “end” for each period entered.
"coll_dates": [
{
"start": "string",
"end": "string",
"cycle": "string"
}
]start[Required ; Not repeatable ; String]
Date the data collection started (for the specified cycle, if any). Enter the date in ISO 8601 format (YYYY-MM-DD or YYYY-MM or YYYY).end[Required ; Not repeatable ; String]
Date the data collection ended (for the specified cycle, if any). Enter the date in ISO 8601 format (YYYY-MM-DD or YYYY-MM or YYYY).cycle[Optional ; Not repeatable ; String]
Identification of the cycle of data collection. Thecycleattribute permits specification of the relevant cycle, wave, or round of data. For example, a household consumption survey could visit households in four phases (one per quarter). Each quarter would be a cycle, and the specific dates of data collection for each quarter would be entered.
This example is for an impact evaluation survey with a baseline and two follow-up surveys)
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
study_info = list(
# ... ,
time_periods = list(
list(start = "2020-01-10",
end = "2020-01-16",
cycle = "Baseline survey"),
list(start = "2020-07-10",
end = "2020-07-16",
cycle = "First follow-up survey"),
list(start = "2021-01-10",
end = "2021-01-16",
cycle = "Second and last follow-up survey"),
),
coll_dates = list(
list(start = "2020-01-17",
end = "2020-01-25",
cycle = "Baseline survey"),
list(start = "2020-07-17",
end = "2020-07-24",
cycle = "First follow-up survey"),
list(start = "2021-01-17",
end = "2021-01-22",
cycle = "Second and last follow-up survey")
),
# ...
),
# ...
) nation[Optional ; Repeatable]
Indicates the country or countries (or “economies”, or “territories”) covered in the study (but not the sub-national geographic areas). If the study covers more than one country, they will be entered separately.
"nation": [
{
"name": "string",
"abbreviation": "string"
}
]name[Required ; Not repeatable ; String]
The country name, even in cases where the study does not cover the entire country.abbreviation[Optional ; Not repeatable ; String]
Theabbreviationwill contain a country code, preferably the 3-letter ISO 3166-1 country code.bbox[Optional ; Repeatable]
This element is used to define one or multiple bounding box(es), which are the rectangular fundamental geometric description of the geographic coverage of the data. A bounding box is defined by west and east longitudes and north and south latitudes, and includes the largest geographic extent of the dataset’s geographic coverage. The bounding box provides the geographic coordinates of the top left (north/west) and bottom-right (south/east) corners of a rectangular area. This element can be used in catalogs as the first pass of a coordinate-based search. This element is optional, but if thebound_polyelement (see below) is used, then thebboxelement must be included.
"bbox": [
{
"west": "string",
"east": "string",
"south": "string",
"north": "string"
}
]west[Required ; Not repeatable ; String]
West longitude of the bounding box.east[Required ; Not repeatable ; String]
East longitude of the bounding box.south[Required ; Not repeatable ; String]
South latitude of the bounding box.north[Required ; Not repeatable ; String]
North latitude of the bounding box.
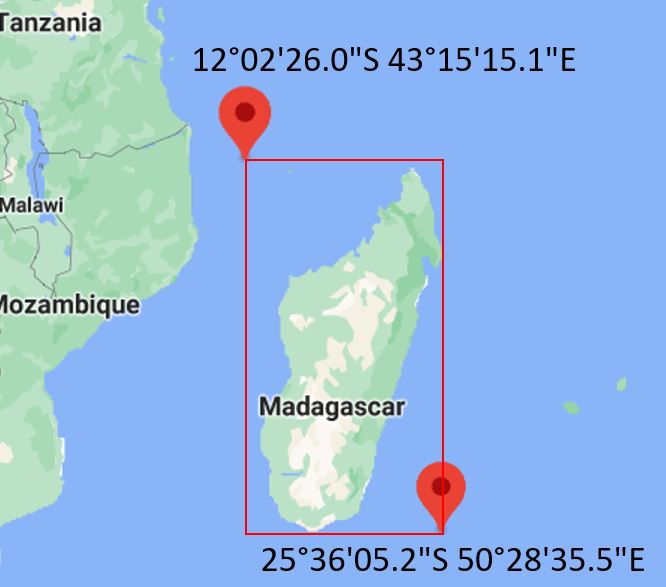
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
study_info = list(
# ... ,
nation = list(
list(name = "Madagascar", abbreviation = "MDG"),
list(name = "Mauritius", abbreviation = "MUS")
),
bbox = list(
list(name = "Madagascar",
west = "43.2541870461",
east = "50.4765368996",
south = "-25.6014344215",
north = "-12.0405567359"),
list(name = "Mauritius",
west = "56.6",
east = "72.466667",
south = "-20.516667",
north = "-5.25")
),
# ...
),
# ...
) bound_poly[Optional ; Repeatable]
Thebboxmetadata element (see above) describes a rectangular area representing the entire geographic coverage of a dataset. The elementbound_polyallows for a more detailed description of the geographic coverage, by allowing multiple and non-rectangular polygons (areas) to be described. This is done by providing list(s) of latitude and longitude coordinates that define the area(s). It should only be used to define the outer boundaries of the covered areas. This field is intended to enable a refined coordinate-based search, not to actually map an area. Note that if thebound_polyelement is used, then the elementbboxMUST be present as well, and all points enclosed by thebound_polyMUST be contained within the bounding box defined inbbox.
"bound_poly": [
{
"lat": "string",
"lon": "string"
}
]lat[Required ; Not repeatable ; String]
The latitude of the coordinate.lon[Required ; Not repeatable ; String]
The longitude of the coordinate.
This example shows a polygon for the State of Nevada, USA
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
study_info = list(
# ... ,
bound_poly = list(
list(lat = "42.002207", lon = "-120.005729004"),
list(lat = "42.002207", lon = "-114.039663"),
list(lat = "35.9", lon = "-114.039663"),
list(lat = "36.080", lon = "-114.544"),
list(lat = "35.133", lon = "-114.542"),
list(lat = "35.00208499998", lon = "-114.63288"),
list(lat = "35.00208499998", lon = "-114.63323"),
list(lat = "38.999", lon = "-120.005729004"),
list(lat = "42.002207", lon = "-120.005729004")
),
# ...
),
# ...
) geog_coverage[Optional ; Not repeatable ; String]Information on the geographic coverage of the study. This includes the total geographic scope of the data, and any additional levels of geographic coding provided in the variables. Typical entries will be “National coverage”, “Urban areas”, “Rural areas”, “State of …”, “Capital city”, etc. This does not describe where the data were collected; it describes which area the data are representative of. This means for example that a sample survey could be declared as having a national coverage even if some districts of the country where not included in the sample, as long as the sample is nationally representative.
geog_coverage_notes[Optional ; Not repeatable ; String]Additional information on the geographic coverage of the study entered as a free text field.
geog_unit[Optional ; Not repeatable ; String]Describes the levels of geographic aggregation covered by the data. Particular attention must be paid to include information on the lowest geographic area for which data are representative.
my_ddi <- list( doc_desc = list( # ... ), study_desc = list( # ... , study_info = list( # ... , geog_coverage = "National coverage", geog_coverage_notes = "The sample covered the urban and rural areas of all provinces of the country. Some areas of province X were however not accessible due to civil unrest.", geog_unit = "The survey provides data representative at the national, provincial and district levels. For the capital city, the data are representative at the ward level.", # ... ), # ... )analysis_unit[Optional ; Not repeatable ; String]A study can have multiple units of analysis. This field will list the various units that can be analyzed. For example, a Living Standard Measurement Study (LSMS) may have collected data on households and their members (individuals), on dwelling characteristics, on prices in local markets, on household enterprises, on agricultural plots, and on characteristics of health and education facilities in the sample areas.
my_ddi <- list( doc_desc = list( # ... ), study_desc = list( # ... , study_info = list( # ... , analysis_unit = "Data were collected on households, individuals (household members), dwellings, commodity prices at local markets, household enterprises, agricultural plots, and characteristics of health and education facilities." # ... ), # ... )universe[Optional ; Not repeatable ; String]The universe is the group of persons (or other units of observations, like dwellings, facilities, or other) that are the object of the study and to which any analytic results refer. The universe will rarely cover the entire population of the country. Sample household surveys, for example, may not cover homeless, nomads, diplomats, community households. Population censuses do not cover diplomats. Facility surveys may be limited to facilities of a certain type (e.g., public schools). Try to provide the most detailed information possible on the population covered by the survey/census, focusing on excluded categories of the population. For household surveys, age, nationality, and residence commonly help to delineate a given universe, but any of a number of factors may be involved, such as sex, race, income, veteran status, criminal convictions, etc. In general, it should be possible to tell from the description of the universe whether a given individual or element (hypothetical or real) is a member of the population under study.
my_ddi <- list( doc_desc = list( # ... ), study_desc = list( # ... , study_info = list( # ... , universe = "The survey covered all de jure household members (usual residents), all women aged 15-49 years resident in the household, and all children aged 0-4 years (under age 5) resident in the household.", # ... ), # ... )data_kind[Optional ; Not repeatable ; String]This field describes the main type of microdata generated by the study: survey data, census/enumeration data, aggregate data, clinical data, event/transaction data, program source code, machine-readable text, administrative records data, experimental data, psychological test, textual data, coded textual, coded documents, time budget diaries, observation data/ratings, process-produced data, etc. A controlled vocabulary should be used as this information may be used to build facets (filters) in a catalog user interface.
my_ddi <- list( doc_desc = list( # ... ), study_desc = list( # ... , study_info = list( # ... , data_kind = "Sample survey data", # ... ), # ... )notes[Optional ; Not repeatable ; String]This element is provided to document any specific situations, observations, or events that occurred during data collection. Consider stating such items like:
- Was a training of enumerators held? (elaborate)
- Was a pilot survey conducted?
- Did any events have a bearing on the data quality? (elaborate)
- How long did an interview take on average?
- In what language(s) were the interviews conducted?
- Were there any corrective actions taken by management when problems occurred in the field?
my_ddi <- list( doc_desc = list( # ... ), study_desc = list( # ... , study_info = list( # ... , notes = "The pre-test for the survey took place from August 15, 2006 - August 25, 2006 and included 14 interviewers who would later become supervisors for the main survey. Each interviewing team comprised of 3-4 female interviewers (no male interviewers were used due to the sensitivity of the subject matter), together with a field editor and a supervisor and a driver. A total of 52 interviewers, 14 supervisors and 14 field editors were used. Training of interviewers took place at the headquarters of the Statistics Office from July 1 to July 12, 2006. Data collection took place over a period of about 6 weeks from September 2, 2006 until October 17, 2006. Interviewing took place everyday throughout the fieldwork period, although interviewing teams were permitted to take one day off per week. Interviews averaged 35 minutes for the household questionnaire (excluding water testing), 23 minutes for the women's questionnaire, and 27 for the under five children's questionnaire (excluding the anthropometry). Interviews were conducted primarily in English, but occasionally used local translation. Six staff members of the Statistics Office provided overall fieldwork coordination and supervision." # ... ), # ... )- Was a training of enumerators held? (elaborate)
quality_statement[Optional ; Not Repeatable]
This section lists the specific standards complied with during the execution of this study, and provides the option to formulate a general statement on the quality of the data. Any known quality issue should be reported here. Such issues are better reported by the data producer or curator, not left to the secondary analysts to discover. Transparency in reporting quality issues will increase credibility and reputation of the data provider.
"quality_statement": {
"compliance_description": "string",
"standards": [
{
"name": "string",
"producer": "string"
}
],
"other_quality_statement": "string"
}compliance_description[Optional ; Not repeatable ; String]
A statement on compliance with standard quality assessment procedures. The list of these standards can be documented in the next element,standards.standards[Optional ; Repeatable]
An itemized list of quality standards complied with during the execution of the study.
name[Optional ; Not repeatable ; String]
The name of the quality standard, if such a standard was used. Include the date when the standard was published, and the version of the standard with which the study is compliant, and the “URI” attribute includes .producer[Optional ; Not repeatable ; String]
The producer of the quality standard mentined inname.
other_quality_statement[Optional ; Not repeatable ; String]
Any additional statement on the quality of the data, entered as free text. This can be independent of any particular quality standard.
@@@ complete the example
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
study_info = list(
# ... ,
quality_statement = list(
compliance_description = "",
standards = list(
list(name = "",
producer = "")
),
other_quality_statement = ""
),
# ...
),
# ...
) ex_post_evaluation[Optional ; Not Repeatable]
Ex-post evaluations are frequently done within large statistical or research organizations, in particular when a study is intended to be repeated. Such evaluations are recommended by the Generic Statistical Business Process Model (GSBPM). This section of the schema is used to describe the evaluation procedures and their outcomes.
"ex_post_evaluation": {
"completion_date": "string",
"type": "string",
"evaluator": [
{
"name": "string",
"affiliation": "string",
"abbr": "string",
"role": "string"
}
],
"evaluation_process": "string",
"outcomes": "string"
}completion_date[Optional ; Not repeatable ; String]
The date the ex-post evaluation was completed.type[Optional ; Not Repeatable]
Thetypeattribute identifies the type of evaluation with or without the use of a controlled vocabulary.evaluator[Optional ; Repeatable]
The evaluator element identifies the person(s) and/or organization(s) involved in the evaluation.
name[Optional ; Not repeatable ; String]
The name of the person or organization involved in the evaluation.affiliation[Optional ; Not repeatable ; String]
The affiliation of the individual or organization mentioned inname.abbr[Optional ; Not repeatable ; String]
An abbreviation for the organization mentioned inname.role[Optional ; Not repeatable ; String]
The specific role played by the individual or organization mentioned innamein the evaluation process.
evaluation_process[Optional ; Not repeatable ; String]
A description of the evaluation process. This may include information on the dates the evaluation was conducted, cost/budget, relevance, institutional or legal arrangements, et.outcomes[Optional ; Not repeatable ; String]
A description of the outcomes of the evaluation. It may include a reference to an evaluation report.
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
study_info = list(
# ... ,
ex_post_evaluation = list(
completion_date = "2020-04-30",
type = "Independent evaluation requested by the survey sponsor",
evaluator = list(
list(name = "John Doe",
affiliation = "Alpha Consulting, Ltd.",
abbr = "AC",
role = "Evaluation of the sampling methodology"),
list(name = "Jane Smith",
affiliation = "Beta Statistical Services, Ltd.",
abbr = "BSS",
role = "Evaluation of the data processing and analysis")
),
evaluation_process = "In-depth review of pre-collection and collection procedures",
outcomes = "The following steps were highly effective in increasing response rates."
)
),
# ...
) 5.4.2.14 Study development
study_development [Optional ; Not repeatable]
"study_development": {
"development_activity": [
{
"activity_type": "string",
"activity_description": "string",
"participants": [
{
"name": "string",
"affiliation": "string",
"role": "string"
}
],
"resources": [
{
"name": "string",
"origin": "string",
"characteristics": "string"
}
],
"outcome": "string"
}
]
}This section is used to describe the process that led to the production of the final output of the study, from its inception/design to the dissemination of the final output.
development_activity[Optional ; Repeatable]
@@@@ missing in schema; must be added then screenshot taken Each activity will be documented separately. The Generic Statistical Business Process Model (GSBPM) provides a useful decomposition of such a process, which can be used to list the activities to be described. This is a repeatable set of metadata elements; each activity should be documented separately.activity_type[Optional ; Not repeatable ; String]
The type of activity. A controlled vocabulary can be used, possibly comprising the main components of the GSBPM:{Needs specification, Design, Build, Collect, Process, Analyze, Disseminate, Evaluate}).activity_description[Optional ; Not repeatable ; String]
A brief description of the activity.participants[Optional ; Repeatable]
A list of participants (persons or organizations) in the activity. This is a repeatable set of elements; each participant can be documented separately.
name[Optional ; Not repeatable ; String]
Name of the participating person or organization.affiliation[Optional ; Not repeatable ; String]
Affiliation of the person or organization mentioned inname.role[Optional ; Not repeatable ; String]
Specific role (participation) of the person or organization mentioned inname.
resources[Optional ; Not Repeatable]
A description of the data sources and other resources used to implement the activity.
name[Optional ; Not repeatable ; String]
The name of the resource.origin[Optional ; Not repeatable ; String]
The origin of the resource mentioned inname.characteristics[Optional ; Not repeatable ; String]
The characteristics of the resource mentioned inname.
outcome[Optional ; Not repeatable ; String]
Description of the main outcome of the activity.
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
study_info = list(
# ... ),
study_development = list(
development_activity = list(
list(
activity_type = "Questionnaire design and piloting",
activity_description = "",
participants = list(
list(name = "",
affiliation = "",
role = ""),
list(name = "",
affiliation = "",
role = ""),
list(name = "",
affiliation = "",
role = "")
),
resources = list(
list(name = "",
origin = "",
characteristics = "")
),
outcome = ""
),
list(
activity_type = "Interviewers training",
activity_description = "",
participants = list(
list(name = "",
affiliation = "",
role = ""),
list(name = "",
affiliation = "",
role = ""),
list(name = "",
affiliation = "",
role = "")
),
resources = list(
list(name = "",
origin = "",
characteristics = "")
),
outcome = ""
)
)
),
# ...
)5.4.2.15 Method
method [Optional ; Not Repeatable]
This section describes the methodology and processing involved in a study.
"method": {
"data_collection": {},
"method_notes": "string",
"analysis_info": {},
"study_class": null,
"data_processing": [],
"coding_instructions": []
}data_collection[Optional ; Not Repeatable]
A block of metadata elements used to describe the methodology employed in a data collection. This includes the design of the questionnaire, sampling, supervision of field work, and other characteristics of the data collection phase.
"data_collection": {
"time_method": "string",
"data_collectors": [],
"collector_training": [],
"frequency": "string",
"sampling_procedure": "string",
"sample_frame": {},
"sampling_deviation": "string",
"coll_mode": null,
"research_instrument": "string",
"instru_development": "string",
"instru_development_type": "string",
"sources": [],
"coll_situation": "string",
"act_min": "string",
"control_operations": "string",
"weight": "string",
"cleaning_operations": "string"
}time_method[Optional ; Not repeatable ; String]
The time method or time dimension of the data collection. A controlled vocabulary can be used. The entries for this element may include “panel survey”, “cross-section”, “trend study”, or “time-series”.data_collectors[Optional ; Not Repeatable]
The entity (individual, agency, or institution) responsible for administering the questionnaire or interview or compiling the data.
"data_collectors": [
{
"name": "string",
"affiliation": "string",
"abbr": "string",
"role": "string"
}
]name[Optional ; Not repeatable ; String]
In most cases, we will record here the name of the agency, not the name of interviewers. Only in the case of very small-scale surveys, with a very limited number of interviewers, the name of persons will be included as well.affiliation[Optional ; Not repeatable ; String]
The affiliation of the data collector mentioned inname.abbr[Optional ; Not repeatable ; String]
The abbreviation given to the agency mentioned inname.role[Optional ; Not repeatable ; String]
The specific role of the person or agency mentioned inname.collector_training[Optional ; Repeatable]
Describes the training provided to data collectors including interviewer training, process testing, compliance with standards etc. This set of elements is repeatable, to capture different aspects of the training process.
"collector_training": [
{
"type": "string",
"training": "string"
}
]type[Optional ; Not repeatable ; String]
The type of training being described. For example, “Training of interviewers”, “Training of controllers”, “Training of cartographers”, “Training on the use of tablets for data collection”, etc.training[Optional ; Not repeatable ; String]
A brief description of the training. This may include information on the dates and duration, audience, location, content, trainers, issues, etc.frequency[Optional ; Not repeatable ; String]
For data collected at more than one point in time, the frequency with which the data were collected.sampling_procedure[Optional ; Not repeatable ; String]
This field only applies to sample surveys. It describes the type of sample and sample design used to select the survey respondents to represent the population. This section should include summary information that includes (but is not limited to): sample size (expected and actual) and how the sample size was decided; level of representation of the sample; sample frame used, and listing exercise conducted to update it; sample selection process (e.g., probability proportional to size or over sampling); stratification (implicit and explicit); design omissions in the sample; strategy for absent respondents/not found/refusals (replacement or not). Detailed information on the sample design is critical to allow users to adequately calculate sampling errors and confidence intervals for their estimates. To do that, they will need to be able to clearly identify the variables in the dataset that represent the different levels of stratification and the primary sampling unit (PSU).
In publications and reports, the description of sampling design often contains complex formulas and symbols. As the XML and JSON formats used to store the metadata are plain text files, they cannot contain these complex representations. You may however provide references (title/author/date) to documents where such detailed descriptions are provided, and make sure that the documents (or links to the documents) are provided in the catalog where the survey metadata are published.sample_frame[Optional ; Not Repeatable]
A description of the sample frame used for identifying the population from which the sample was taken. For example, a telephone book may be a sample frame for a phone survey. Or the listing of enumeration areas (EAs) of a population census can provide a sample frame for a household survey. In addition to the name, label and text describing the sample frame, this structure lists who maintains the sample frame, the period for which it is valid, a use statement, the universe covered, the type of unit contained in the frame as well as the number of units available, the reference period of the frame and procedures used to update the frame.
"sample_frame": {
"name": "string",
"valid_period": [
{
"event": "string",
"date": "string"
}
],
"custodian": "string",
"universe": "string",
"frame_unit": {
"is_primary": null,
"unit_type": "string",
"num_of_units": "string"
},
"reference_period": [
{
"event": "string",
"date": "string"
}
],
"update_procedure": "string"
}name[Optional ; Not Repeatable]
The name (title) of the sample frame.valid_period[Optional ; Repeatable]
Defines a time period for the validity of the sampling frame, using a list of events and dates.event[Optional ; Not repeatable ; String]
The event can for example bestartorend.date[Optional ; Not repeatable ; String]
The date corresponding to the event, entered in ISO 8601 format: YYYY-MM-DD.
custodian[ Optional ; Not Repeatable]
Custodian identifies the agency or individual responsible for creating and/or maintaining the sample frame.universe[Optional ; Not Repeatable]
A description of the universe of population covered by the sample frame. Age,nationality, and residence commonly help to delineate a given universe, but any of a number of factors may be involved, such as sex, race, income, etc. The universe may consist of elements other than persons, such as housing units, court cases, deaths, countries, etc. In general, it should be possible to tell from the description of the universe whether a given individual or element (hypothetical or real) is included in the sample frame.frame_unit[Optional ; Not Repeatable]
Provides information about the sampling frame unit.is_primary[Optional ; Boolean ; Not Repeatable]
This boolean attribute (true/false) indicates whether the unit is primary or not.unit_type[Optional ; Not repeatable ; String]
The type of the sampling frame unit (for example “household”, or “dwelling”).num_of_units[Optional ; Not Repeatable ; String]
The number of units in the sample frame, possibly with information on its distribution (e.g. by urban/rural, province, or other).
reference_period[Optional ; Not Repeatable]
Indicates the period of time in which the sampling frame was actually used for the study in question. Use ISO 8601 date format to enter the relevant date(s).event[Optional ; Not repeatable ; String]
Indicates the type of event that the date corresponds to, e.g., “start”, “end”, “single”.date[Optional ; Not repeatable ; String]
The relevant date in ISO 8601 date/time format.
update_procedure[Optional ; Not repeatable ; String]
This element is used to describe how and with what frequency the sample frame is updated. For example: “The lists and boundaries of enumeration areas are updated every ten years at the occasion of the population census cartography work. Listing of households in enumeration areas are updated as and when needed, based on their selection in survey samples.”sampling_deviation[Optional ; Not repeatable ; String]
Sometimes the reality of the field requires a deviation from the sampling design (for example due to difficulty to access to zones due to weather problems, political instability, etc). If for any reason, the sample design has deviated, this can be reported here. This element will provide information indicating the correspondence as well as the possible discrepancies between the sampled units (obtained) and available statistics for the population (age, sex-ratio, marital status, etc.) as a whole.
coll_mode[Optional ; Repeatable ; String]
The mode of data collection is the manner in which the interview was conducted or information was gathered. Ideally, a controlled vocabulary will be used to constrain the entries in this field (which could include items like “telephone interview”, “face-to-face paper and pen interview”, “face-to-face computer-assisted interviews (CAPI)”, “mail questionnaire”, “computer-aided telephone interviews (CATI)”, “self-administered web forms”, “measurement by sensor”, and others.
This is a repeatable field, as some data collection activities implement multi-mode data collection (for example, a population census can offer respondents the options to submit information via web forms, telephone interviews, mailed forms, or face-to-face interviews. Note that in the API description (see screenshot above), the element is described as having type “null”, not {}. This is due to the fact that the element can be entered either as a list (repeatable element) or as a string.
research_instrument[Optional ; Not repeatable ; String]
The research instrument refers to the questionnaire or form used for collecting data. The following should be mentioned:
- List of questionnaires and short description of each (all questionnaires must be provided as External Resources)
- In what language(s) was/were the questionnaire(s) available?
- Information on the questionnaire design process (based on a previous questionnaire, based on a standard model questionnaire, review by stakeholders). If a document was compiled that contains the comments provided by the stakeholders on the draft questionnaire, or a report prepared on the questionnaire testing, a reference to these documents can be provided here.
instru_development[Optional ; Not repeatable ; String]
Describe any development work on the data collection instrument. This may include a description of the review process, standards followed, and a list of agencies/people consulted.
instru_development_type[Optional ; Repeatable ; String]
The instrument development type. This element will be used when a pre-defined list of options (controlled vocabulary) is available.
sources[Optional ; Repeatable]
A description of sources used for developing the methodology of the data collection.
"sources": [
{
"name": "string",
"origin": "string",
"characteristics": "string"
}
]name[Optional ; Not repeatable ; String]
The name and other information on the source. For example, “United States Internal Revenue Service Quarterly Payroll File”origin[Optional ; Not repeatable ; String]
For historical materials, information about the origin(s) of the sources and the rules followed in establishing the sources should be specified. This may not be relevant to survey data.characteristics[Optional ; Not repeatable ; String]
Assessment of characteristics and quality of source material. This may not be relevant to survey data.coll_situation[Optional ; Not repeatable ; String]
A description of noteworthy aspects of the data collection situation. Includes information on factors such as cooperativeness of respondents, duration of interviews, number of call-backs, etc.
act_min[Optional ; Not repeatable ; String]
A summary of actions taken to minimize data loss. This includes information on actions such as follow-up visits, supervisory checks, historical matching, estimation, etc. Note that this element does not have to include detailed information on response rates, as a specific metadata element is provided for that purpose in section analysis_info / response_rate (see below).
control_operations[Optional ; Not repeatable ; String]
This element will provide information on the oversight of the data collection, i.e. on methods implemented to facilitate data control performed by the primary investigator or by the data archive.
weight[Optional ; Not repeatable ; String]
This field only applies to sample surveys. The use of sampling procedures may make it necessary to apply weights to produce accurate statistical results. Describe here the criteria for using weights in analysis of a collection, and provide a list of variables used as weighting coefficient. If more than one variable is a weighting variable, describe how these variables differ from each other and what the purpose of each one of them is.
cleaning_operations[Optional ; Not repeatable ; String]
A description of the methods used to clean or edit the data, e.g., consistency checking, wild code checking, etc. The data editing should contain information on how the data was treated or controlled for in terms of consistency and coherence. This item does not concern the data entry phase but only the editing of data whether manual or automatic. It should provide answers to questions like: Was a hot deck or a cold deck technique used to edit the data? Were corrections made automatically (by program), or by visual control of the questionnaire? What software was used? If materials are available (specifications for data editing, report on data editing, programs used for data editing), they should be listed here and provided as external resources in data catalogs (the best documentation of data editing consists of well-documented reproducible scripts).
Example for the data_collection section:
```r
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
study_info = list(
# ... ),
study_development = list(
# ... ),
method = list(
data_collection = list(
time_method = "cross-section",
data_collectors = list(
list(name = "Staff from the Central Statistics Office",
abbr = "NSO",
affiliation = "Ministry of Planning")
),
collector_training = list(
list(
type = "Training of interviewers",
training = "72 staff (interviewers) were trained from [date] to [date] at the NSO headquarters. The training included 2 days of field work."
),
list(
type = "Training of controllers and supervisors",
training = "A 3-day training of 10 controlers and 2 supervisors was organized from [date] to [date]. The controllers and supervisors had previously participated in the interviewer training."
)
),
sampling_procedure = "A list of 500 Enumeration Areas (EAs) were randomly selected from the sample frame, 300 in urban areas and 200 in rural areas. In each selected EA, 10 households were then randomly selected. 5000 households were thus selected for the sample (3000 urban and 2000 rural). The distribution of the sample (households) by province is as follows:
- Province A: Total: 1800 Urban: 1000 Rural: 800
- Province B: Total: 1200 Urban: 500 Rural: 700
- Province C: Total: 2000 Urban: 1500 Rural: 500",
sample_frame = list(
name = "Listing of Enumeration Areas (EAs) from the Population and Housing Census 2011",
custodian = "National Statistics Office",
universe = "The sample frame contains 25365 EAs covering the entire territory of the country. EAs contain an average of 400 households in rural areas, and 580 in urban areas. ",
frame_unit = list(
is_primary = true,
unit_type = "Enumeration areas (EAs)",
num_of_units = "25365, including 15100 in urban areas, and 10265 in rural areas."
),
update_procedure = "The sample frame only provides EAs; a full household listing was conducted in each selected EA to provide an updated list of households."
),
sampling_deviation = "Due to floods in two sampled rural in province A, two EAs could not be reached. The sample was thus reduced to 4980 households. The response rate was 90%, so the actual final sample size was 4482 households.",
coll_mode = "Face-to-face interviews, conducted using tablets (CAPI)",
research_instrument = "The questionnaires for the Generic MICS were structured questionnaires based on the MICS3 Model Questionnaire with some modifications and additions. A household questionnaire was administered in each household, which collected various information on household members including sex, age, relationship, and orphanhood status. The household questionnaire includes household characteristics, support to orphaned and vulnerable children, education, child labour, water and sanitation, household use of insecticide treated mosquito nets, and salt iodization, with optional modules for child discipline, child disability, maternal mortality and security of tenure and durability of housing.
In addition to a household questionnaire, questionnaires were administered in each household for women age 15-49 and children under age five. For children, the questionnaire was administered to the mother or caretaker of the child.
The women's questionnaire include women's characteristics, child mortality, tetanus toxoid, maternal and newborn health, marriage, polygyny, female genital cutting, contraception, and HIV/AIDS knowledge, with optional modules for unmet need, domestic violence, and sexual behavior.
The children's questionnaire includes children's characteristics, birth registration and early learning, vitamin A, breastfeeding, care of illness, malaria, immunization, and anthropometry, with an optional module for child development.
The questionnaires were developed in English from the MICS3 Model Questionnaires and translated into local languages. After an initial review the questionnaires were translated back into English by an independent translator with no prior knowledge of the survey. The back translation from the local language version was independently reviewed and compared to the English original. Differences in translation were reviewed and resolved in collaboration with the original translators. The English and local language questionnaires were both piloted as part of the survey pretest.",
instru_development = "The questionnaire was pre-tested with split-panel tests, as well as an analysis of non-response rates for individual items, and response distributions.",
coll_situation = "Floods in province A made access to two selected enumeration areas impossible.",
act_min = "Local authorities and local staff from the Ministry of Health contributed to an awareness campaign, which contributed to achieving a response rate of 90%.",
control_operations = "Interviewing was conducted by teams of interviewers. Each interviewing team comprised of 3-4 female interviewers, a field editor and a supervisor, and a driver. Each team used a 4 wheel drive vehicle to travel from cluster to cluster (and where necessary within cluster).
The role of the supervisor was to coordinate field data collection activities, including management of the field teams, supplies and equipment, finances, maps and listings, coordinate with local authorities concerning the survey plan and make arrangements for accommodation and travel. Additionally, the field supervisor assigned the work to the interviewers, spot checked work, maintained field control documents, and sent completed questionnaires and progress reports to the central office.
The field editor was responsible for validating questionnaires at the end of the day when the data form interviews were transferred to their laptops. This included checking for missed questions, skip errors, fields incorrectly completed, and checking for inconsistencies in the data. The field editor also observed interviews and conducted review sessions with interviewers.
Responsibilities of the supervisors and field editors are described in the Instructions for Supervisors and Field Editors, together with the different field controls that were in place to control the quality of the fieldwork.
Field visits were also made by a team of central staff on a periodic basis during fieldwork. The senior staff of NSO also made 3 visits to field teams to provide support and to review progress.",
weight = "Sample weights were calculated for each of the data files. Sample weights for the household data were computed as the inverse of the probability of selection of the household, computed at the sampling domain level (urban/rural within each region). The household weights were adjusted for non-response at the domain level, and were then normalized by a constant factor so that the total weighted number of households equals the total unweighted number of households. The household weight variable is called HHWEIGHT and is used with the HH data and the HL data.
Sample weights for the women's data used the un-normalized household weights, adjusted for non-response for the women's questionnaire, and were then normalized by a constant factor so that the total weighted number of women's cases equals the total unweighted number of women's cases.
Sample weights for the children's data followed the same approach as the women's and used the un-normalized household weights, adjusted for non-response for the children's questionnaire, and were then normalized by a constant factor so that the total weighted number of children's cases equals the total unweighted number of children's cases.",
cleaning_operations = "Data editing took place at a number of stages throughout the processing, including:
a) Office editing and coding
b) During data entry
c) Structure checking and completenes
d) Secondary editing
e) Structural checking of SPSS data files
Detailed documentation of the editing of data can be found in the 'Data processing guidelines' document provided as an external resource."
)
)
),
# ...
)
)
```method_notes[Optional ; Not repeatable ; String]
This element is provided to capture any additional relevant information on the data collection methodology, which could not fit in the previous metadata elements.
analysis_info[Optional ; Not Repeatable]
This block of elements is used to organize information related to data quality and appraisal.
"analysis_info": {
"response_rate": "string",
"sampling_error_estimates": "string",
"data_appraisal": "string"
}response_rate[Optional ; Not repeatable ; String]
The response rate is the percentage of sample units that participated in the survey based on the original sample size. Omissions may occur due to refusal to participate, impossibility to locate the respondent, or other reason. This element is used to provide a narrative description of the response rate, possibly by stratum or other criteria, and if possible with an identification of possible causes. If information is available on the causes of non-response (refusal/not found/other), it can be reported here. This field can also be used to describe non-responses in population censuses.sampling_error_estimates[Optional ; Not repeatable ; String]
Sampling errors are intended to measure how precisely one can estimate a population value from a given sample. For sampling surveys, it is good practice to calculate and publish sampling error. This field is used to provide information on these calculations (not to provide the sampling errors themselves, which should be made available in publications or reports). Information can be provided on which ratios/indicators have been subjected to the calculation of sampling errors, and on the software used for computing the sampling error. Reference to a report or other document where the results can be found can also be provided.data_appraisal[Optional ; Not repeatable ; String]
This section is used to report any other action taken to assess the reliability of the data, or any observations regarding data quality. Describe here issues such as response variance, interviewer and response bias, question bias, etc. For a population census, this can include information on the main results of a post enumeration survey (a report should be provided in external resources and mentioned here); it can also include relevant comparisons with data from other sources that can be used as benchmarks.
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
study_info = list(
# ... ),
study_development = list(
# ... ),
method = list(
# ... ,
analysis_info = list(
response_rate = "Of these, 4996 were occupied households and 4811 were successfully interviewed for a response rate of 96.3%. Within these households, 7815 eligible women aged 15-49 were identified for interview, of which 7505 were successfully interviewed (response rate 96.0%), and 3242 children aged 0-4 were identified for whom the mother or caretaker was successfully interviewed for 3167 children (response rate 97.7%). These give overall response rates (household response rate times individual response rate) for the women's interview of 92.5% and for the children's interview of 94.1%.",
sampling_error_estimates = "Estimates from a sample survey are affected by two types of errors: 1) non-sampling errors and 2) sampling errors. Non-sampling errors are the results of mistakes made in the implementation of data collection and data processing. Numerous efforts were made during implementation of the 2005-2006 MICS to minimize this type of error, however, non-sampling errors are impossible to avoid and difficult to evaluate statistically. If the sample of respondents had been a simple random sample, it would have been possible to use straightforward formulae for calculating sampling errors. However, the 2005-2006 MICS sample is the result of a multi-stage stratified design, and consequently needs to use more complex formulae. The SPSS complex samples module has been used to calculate sampling errors for the 2005-2006 MICS. This module uses the Taylor linearization method of variance estimation for survey estimates that are means or proportions. This method is documented in the SPSS file CSDescriptives.pdf found under the Help, Algorithms options in SPSS.
Sampling errors have been calculated for a select set of statistics (all of which are proportions due to the limitations of the Taylor linearization method) for the national sample, urban and rural areas, and for each of the five regions. For each statistic, the estimate, its standard error, the coefficient of variation (or relative error - the ratio between the standard error and the estimate), the design effect, and the square root design effect (DEFT - the ratio between the standard error using the given sample design and the standard error that would result if a simple random sample had been used), as well as the 95 percent confidence intervals (+/-2 standard errors). Details of the sampling errors are presented in the sampling errors appendix to the report and in the sampling errors table presented in the external resources.",
data_appraisal = "A series of data quality tables and graphs are available to review the quality of the data and include the following:
- Age distribution of the household population
- Age distribution of eligible women and interviewed women
- Age distribution of eligible children and children for whom the mother or caretaker was interviewed
- Age distribution of children under age 5 by 3 month groups
- Age and period ratios at boundaries of eligibility
- Percent of observations with missing information on selected variables
- Presence of mother in the household and person interviewed for the under 5 questionnaire
- School attendance by single year age
- Sex ratio at birth among children ever born, surviving and dead by age of respondent
- Distribution of women by time since last birth
- Scatter plot of weight by height, weight by age and height by age
- Graph of male and female population by single years of age
- Population pyramid
The results of each of these data quality tables are shown in the appendix of the final report.
The general rule for presentation of missing data in the final report tabulations is that a column is presented for missing data if the percentage of cases with missing data is 1% or more. Cases with missing data on the background characteristics (e.g. education) are included in the tables, but the missing data rows are suppressed and noted at the bottom of the tables in the report."
),
# ...
)
# ...
) study_class[Optional ; Repeatable ; String]
This element can be used to give the data archive’s class or study status number, which indicates the processing status of the study. But it can also be used as an element to indicate the type of study, based on a controlled vocabulary. The element is repeatable, allowing one study to belong to more than one class. Note that in the API description (see screenshot above), the element is described as having type “null”, not {}. This is due to the fact that the element can be entered either as a list (repeatable element) or as a string.
data_processing[Optional ; Repeatable]
@@@@ Improve definition of elements
"data_processing": [
{
"type": "string",
"description": "string"
}
]This element is used to describe how data were electronically captured (e.g., entered in the field, in a centralized manner by data entry clerks, captured electronically using tablets and a CAPI application, via web forms, etc.). Information on devices and software used for data capture can also be provided here. Other data processing procedures not captured elsewhere in the documentation can be described here (tabulation, etc.)
- type [Optional ; Not repeatable ; String]
The type attribute supports better classification of this activity, including the optional use of a controlled vocabulary. The vocabulary could include options like “data capture”, “data validation”, “variable derivation”, “tabulation”, “data visualizations”, anonymization“, ”documentation”, etc.
- description [Optional ; Repeatable ; String]
A description of a data processing task.
coding_instructions[Optional ; Repeatable]
Thecoding_instructionselements can be used to describe specific coding instructions used in data processing, cleaning, or tabulation. Providing this information may however be complex and very tedious for datasets with a significant number of variables, where hundreds of commands are used to process the data. An alternative option, preferable in many cases, will be to publish reproducible data editing, tabulation and analysis scripts together with the data, as related resources.
"coding_instructions": [
{
"related_processes": "string",
"type": "string",
"txt": "string",
"command": "string",
"formal_language": "string"
}
]related_processes[Optional ; Not repeatable ; String]
Therelated_processeslinks a coding instruction to one or more processes such as “data editing”, “recoding”, “imputations and derivations”, “tabulation”, etc.type[Optional ; Not repeatable ; String]
The “type” attribute supports the classification of this activity (e.g. “topcoding”). A controlled vocabulary can be used.txt[Optional ; Not repeatable ; String]
A description of the code/command, in a human readable form.command[Optional ; Not repeatable ; String]
The command code for the coding instruction.formal_language[Optional ; Not repeatable ; String]
The language of the command code, e.g. “Stata”, “R”, “SPSS”, “SAS”, “Python”, etc.
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
study_info = list(
# ... ),
study_development = list(
# ... ),
method = list(
# ... ,
study_class = "",
data_processing = list(
list(type = "Data capture",
description = "Data collection was conducted using tablets and Survey Solutions software. Multiple quality controls and validations are embedded in the questionnaire."),
list(type = "Batch data editing",
description = "Data editing was conducted in batch using a R script, including techniques of hot deck, imputations, and recoding."),
list(type = "Tabulation and visualizations",
description = "The 25 tables and the visualizations published in the survey report were produced using Stata (script 'tabulation.do')."),
list(type = "Anonymization",
description = "An anonymized version of the dataset, published as a public use file, was created using the R package sdcMicro.")
),
coding_instructions = list(
list(related_processes = "",
type = "",
txt = "Suppression of observations with ...",
command = "",
formal_language = "Stata"),
list(related_processes = "",
type = "",
txt = "Top coding age",
command = "",
formal_language = "Stata"),
list(related_processes = "",
type = "",
txt = "",
command = "",
formal_language = "Stata")
)
)
# ...
) 5.4.2.16 Data access
data_access [Optional ; Not Repeatable]
This section describes the access conditions and terms of use for the dataset. This set of elements should be used when the access conditions are well-defined and are unlikely to change. An alternative option is to document the terms of use in the catalog where the data will be published, instead of “freezing” them in a metadata file.
"data_access": {
"dataset_availability": {
"access_place": "string",
"access_place_url": "string",
"original_archive": "string",
"status": "string",
"coll_size": "string",
"complete": "string",
"file_quantity": "string",
"notes": "string"
},
"dataset_use": {}
}dataset_availability[Optional ; Not Repeatable]
Information on the availability and storage of the dataset.access_place[Optional ; Not repeatable ; String]
Name of the location where the data collection is currently stored.access_place_url[Optional ; Not repeatable ; String]
The URL of the website of the location where the data collection is currently stored.original_archive[Optional ; Not repeatable ; String]
Archive from which the data collection was obtained, if any (the originating archive). Note that the schema we propose provides an elementprovenance, which is not part of the DDI, that can be used to document the origin of a dataset.status[Optional ; Not repeatable ; String]
A statement of the data availability. An archive may need to indicate that a collection is unavailable because it is embargoed for a period of time, because it has been superseded, because a new edition is imminent, etc. This element will rarely be used.coll_size[Optional ; Not repeatable ; String]
Extent of the collection. This is a summary of the number of physical files that exist in a collection. We will record here the number of files that contain data and note whether the collection contains other machine-readable documentation and/or other supplementary files and information such as data dictionaries, data definition statements, or data collection instruments. This element will rarely be used.complete[Optional ; Not repeatable ; String]
This item indicates the relationship of the data collected to the amount of data coded and stored in the data collection. Information as to why certain items of collected information were not included in the data file stored by the archive should be provided here. Example: “Because of embargo provisions, data values for some variables have been masked. Users should consult the data definition statements to see which variables are under embargo.” This element will rarely be used.file_quantity[Optional ; Not repeatable ; String]
The total number of physical files associated with a collection. This element will rarely be used.notes[Optional ; Not repeatable ; String]
Additional information on the dataset availability, not included in one of the elements above.
my_ddi <- list( doc_desc = list( # ... ), study_desc = list( # ... , study_info = list( # ... ), study_development = list( # ... ), method = list( # ...), data_access = list( dataset_availability = list( access_place = "World Bank Microdata Library", access_place_url = "http://microdata.worldbank.org", status = "Available for public use", coll_size = "4 data files + machine-readable questionnaire and report (2 PDF files) + data editing script (1 Stata do file).", complete = "The variables 'latitude' and 'longitude' (GPS location of respondents) is not included, for confidentiality reasons.", file_quantity = "7" ), # ... ) ) # ... )dataset_use[Optional ; Not Repeatable]
Information on the terms of use for the study dataset.
"dataset_use": {
"conf_dec": [
{
"txt": "string",
"required": "string",
"form_url": "string",
"form_id": "string"
}
],
"spec_perm": [
{
"txt": "string",
"required": "string",
"form_url": "string",
"form_id": "string"
}
],
"restrictions": "string",
"contact": [
{
"name": "string",
"affiliation": "string",
"uri": "string",
"email": "string"
}
],
"cit_req": "string",
"deposit_req": "string",
"conditions": "string",
"disclaimer": "string"
}conf_dec[Optional ; Repeatable]
This element is used to determine if signing of a confidentiality declaration is needed to access a resource. We may indicate here what Affidavit of Confidentiality must be signed before the data can be accessed. Another option is to include this information in the next element (Access conditions). If there is no confidentiality issue, this field can be left blank.txt[Optional ; Not repeatable ; String]
A statement on confidentiality and limitations to data use. This statement does not replace a more comprehensive data agreement (seeAccess condition). An example of statement could be the following: “Confidentiality of respondents is guaranteed by Articles N to NN of the National Statistics Act of [date]. Before being granted access to the dataset, all users have to formally agree:
- To make no copies of any files or portions of files to which s/he is granted access except those authorized by the data depositor.
- Not to use any technique in an attempt to learn the identity of any person, establishment, or sampling unit not identified on public use data files.
- To hold in strictest confidence the identification of any establishment or individual that may be inadvertently revealed in any documents or discussion, or analysis.
- That such inadvertent identification revealed in her/his analysis will be immediately and in confidentiality brought to the attention of the data depositor.”
- To make no copies of any files or portions of files to which s/he is granted access except those authorized by the data depositor.
required[Optional ; Not repeatable ; String]
The “required” attribute is used to aid machine processing of this element. The default specification is “yes”.form_url[Optional ; Not repeatable ; String]
The"form_urlelement is used to provide a link to an online confidentiality declaration form.form_id[Optional ; Not repeatable ; String]
Indicates the number or ID of the confidentiality declaration form that the user must fill out.
spec_perm[Optional ; Repeatable]
This element is used to determine if any special permissions are required to access a resource.txt[Optional ; Not repeatable ; String]
A statement on the special permissions required to access the dataset.required[Optional ; Not repeatable ; String]
Therequiredis used to aid machine processing of this element. The default specification is “yes”.form_url[Optional ; Not repeatable ; String]
Theform_urlis used to provide a link to a special on-line permissions form.form_id[Optional ; Not repeatable ; String]
The “form_id” indicates the number or ID of the special permissions form that the user must fill out.
restrictions[Optional ; Not repeatable ; String]
Any restrictions on access to or use of the collection such as privacy certification or distribution restrictions should be indicated here. These can be restrictions applied by the author, producer, or distributor of the data. This element can for example contain a statement (extracted from the DDI documentation) like: “In preparing the data file(s) for this collection, the National Center for Health Statistics (NCHS) has removed direct identifiers and characteristics that might lead to identification of data subjects. As an additional precaution NCHS requires, under Section 308(d) of the Public Health Service Act (42 U.S.C. 242m), that data collected by NCHS not be used for any purpose other than statistical analysis and reporting. NCHS further requires that analysts not use the data to learn the identity of any persons or establishments and that the director of NCHS be notified if any identities are inadvertently discovered. Users ordering data are expected to adhere to these restrictions.”contact[Optional ; Repeatable]
Users of the data may need further clarification and information on the terms of use and conditions to access the data. This set of elements is used to identify the contact persons who can be used as resource persons regarding problems or questions raised by the user community.name[Optional ; Not repeatable ; String]
Name of the person. Note that in some cases, it might be better to provide a title/function than the actual name of the person. Keep in mind that people do not stay forever in their position.affiliation[Optional ; Not repeatable ; String]
Affiliation of the person.uri[Optional ; Not repeatable ; String]
URI for the person; it can be the URL of the organization the person belongs to.email[Optional ; Not repeatable ; String]
Theemailelement is used to indicate an email address for the contact individual mentioned inname. Ideally, a generic email address should be provided. It is easy to configure a mail server in such a way that all messages sent to the generic email address would be automatically forwarded to some staff members.
cit_req[Optional ; Not repeatable ; String]
A citation requirement that indicates the way that the dataset should be referenced when cited in any publication. Providing a citation requirement will guarantee that the data producer gets proper credit, and that results of analysis can be linked to the proper version of the dataset. The data access policy should explicitly mention the obligation to comply with the citation requirement. The citation should include at least the primary investigator, the name and abbreviation of the dataset, the reference year, and the version number. Include also a website where the data or information on the data is made available by the official data depositor. Ideally, the citation requirement will include a DOI (see the DataCite website for recommendations).deposit_req[Optional ; Not repeatable ; String]
Information regarding data users’ responsibility for informing archives of their use of data through providing citations to the published work or providing copies of the manuscripts.conditions[Optional ; Not repeatable ; String]
Indicates any additional information that will assist the user in understanding the access and use conditions of the data collection.disclaimer[Optional ; Not repeatable ; String]
A disclaimer limits the liability that the data producer or data custodian has regarding the use of the data. A standard legal statement should be used for all datasets from a same agency. The following formulation could be used: The user of the data acknowledges that the original collector of the data, the authorized distributor of the data, and the relevant funding agency bear no responsibility for use of the data or for interpretations or inferences based upon such uses.
Example
```r
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ... ,
study_info = list(
# ... ),
study_development = list(
# ... ),
method = list(
# ...),
data_access = list(
# ...,
dataset_use = list(
conf_dec = list(
list(txt = "Confidentiality of respondents is guaranteed by Articles N to NN of the National Statistics Act. All data users are required to sign an affidavit of confidentiality.",
required = "yes",
form_url = "http://datalibrary.org/affidavit",
form_id = "F01_AC_v01")
),
spec_perm = list(
list(txt = "Permission will only be granted to residents of [country].",
required = "yes",
form_url = "http://datalibrary.org/residency",
form_id = "F02_RS_v01")
),
restrictions = "Data will only be shared with users who are registered to the National Data Center and have successfuly completed the training on data privacy and responsible data use. Only users who legally reside in [country] will be authorized to access the data.",
contact = list(
list(name = "Head, Data Processing Division",
affiliation = "National Statistics Office",
uri = "www.cso.org/databank",
email = "dataproc@cso.org")
),
cit_req = "National Statistics Office of Popstan. Multiple Indicators Cluster Survey 2000 (MICS 2000). Version 01 of the scientific use dataset (April 2001). DOI: XXX-XXXX-XXX",
deposit_req = "To provide funding agencies with essential information about use of archival resources and to facilitate the exchange of information among researchers and development practitioners, users of the Microdata Library data are requested to send to the Microdata Library bibliographic citations for, or copies of, each completed manuscript or thesis abstract. Please indicate in a cover letter which data were used.",
disclaimer = "The user of the data acknowledges that the original collector of the data, the authorized distributor of the data, and the relevant funding agency bear no responsibility for use of the data or for interpretations or inferences based upon such uses."
)
),
# ...
)
```notes[Optional ; Not repeatable ; String]
Any additional information related to data access that is not contained in the specific metadata elements provided in the sectiondata_access.
5.4.3 Description of data files
data_files [Optional ; Repeatable]
The data_files section is the DDI section that contains the elements needed to describe each data file that form the study dataset. These are elements at the file level; it does not include the information at the variable level, which are contained in a separate section of the standard.
"data_files": [
{
"file_id": "string",
"file_name": "string",
"file_type": "string",
"description": "string",
"case_count": 0,
"var_count": 0,
"producer": "string",
"data_checks": "string",
"missing_data": "string",
"version": "string",
"notes": "string"
}
]file_id[Optional ; Not repeatable ; String]
A unique file identifier (within the metadata document, not necessarily within a catalog). This will typically be the electronic file name.file_name[Optional ; Not repeatable ; String]
This is not the name of the electronic file (which is provided in the previous element). It is a short title (label) that will help distinguish a particular file/part from other files/parts in the dataset.file_type[Optional ; Not repeatable ; String]
The type of data files. For example, raw data (ASCII), or software-dependent files such as SAS / Stata / SPSS data file, etc. Provide specific information (e.g. Stata 10 or Stata 15, SPSS Windows or SPSS Export, etc.) Note that in an on-line catalog, data can be made available in multiple formats. In such case, thefile_typeelement is not useful.description[Optional ; Not repeatable ; String]
Thefile_idandfile_nameelements provide limited information on the content of the file. Thedescriptionelement is used to provide a more detailed description of the file content. This description should clearly distinguish collected variables and derived variables. It is also useful to indicate the availability in the data file of some particular variables such as the weighting coefficients. If the file contains derived variables, it is good practice to refer to the computer program that generated it. Information about the data file(s) that comprises a collection.case_count[Optional ; Numeric ; Not Repeatable]
Number of cases or observations in the data file. The value is 0 by default.var_count[Optional ; Numeric ; Not Repeatable]
Number of variables in the data file. The value is 0 by default.producer[Optional ; Not repeatable ; String]
The name of the agency that produced the data file. Most data files will have been produced by the survey primary investigator. In some cases however, auxiliary or derived files from other producers may be released with a data set. This may for example be a file containing derived variables generated by a researcher.data_checks[Optional ; Not repeatable ; String]
Use this element if needed to provide information about the types of checks and operations that have been performed on the data file to make sure that the data are as correct as possible, e.g. consistency checking, wildcode checking, etc. Note that the information included here should be specific to the data file. Information about data processing checks that have been carried out on the data collection (study) as a whole should be provided in theData editingelement at the study level. You may also provide here a reference to an external resource that contains the specifications for the data processing checks (that same information may be provided also in theData Editingfiled in theStudy Descriptionsection).missing_data[Optional ; Not repeatable ; String]
A description of missing data (number of missing cases, cause of missing values, etc.)version[Optional ; Not repeatable ; String]
The version of the data file. A data file may undergo various changes and modifications. File specific versions can be tracked in this element. This field will in most cases be left empty.notes[Optional ; Not repeatable ; String]
This field aims to provide information on the specific data file not covered elsewhere.Example for UNICEF MICS dataset
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ...
),
data_files = list(
list(file_id = "HHS2020_S01",
file_name = "Household roster (demographics)",
description = "The file contains the demographic information on all individuals in the sample",
case_count: 10000,
var_count: 12,
producer = "National Statistics Office",
missing_data = "Values of age outside valid range (0 to 100) have been replaced with 'missing'.",
version = "1.0 (edited, not anonymized)",
notes = ""
),
list(file_id = "HHS2020_S03A",
file_name = "Section 3A - Education",
description = "The file contains data related to section 3A of the household survey questionnaire (Education of household members aged 6 to 24 years). It also contains the weighting coefficient, and various recoded variables on levels of education.",
case_count: 2500,
var_count: 17,
producer = "National Statistics Office",
data_checks = "Education level (variable EDUCLEV) has been edited using hotdeck imputation when the reported value was out of acceptable range considering the AGE of the person.",
version = "1.0 (edited, not anonymized)"
),
list(file_id = "HHS2020_CONSUMPTION",
file_name = "Annualized household consumption by products and services",
description = "The file contains derived data on household consumption, annualized and aggregated by category of products and services. The file also contains a regional price deflator variable and the household weighting coefficient. The file was generated using a Stata program named 'cons_aggregate.do'.",
case_count: 42000,
var_count: 15,
producer = "National Statistics Office",
data_checks = "Outliers have been detected (> median + 5*IQR) for each product/service; fixed by imputation (regression model).",
missing_data = "Missing consumption values are treated as 0",
version = "1.0 (edited, not anonymized)"
)
),
# ...
) 5.4.4 Variable description
The DDI Codebook metadata standard provides multiple elements to document variables contained in a micro-dataset. There is much value in documenting variables: - it makes the data usable by providing users with a detailed data dictionary; - it makes the data more discoverable as all keywords included in the description of variables are indexed in data catalogs; - it allows users to assess the comparability of data across sources; - it enables the development of question banks; and - it adds transparency and credibility to the data especially when derived or imputed variables are documented. All possible effort should thus be made to generate and publish detailed variable-level documentation.
A micro-dataset can contain many variables. Some survey datasets include hundreds or event thousands of variables. Documenting variables can thus be a tedious process. The use of a specialized DDI metadata editor can make this process considerably more efficient. Much of the variable-level metadata can indeed be automatically extracted from the electronic data files. Data files in Stata, SPSS or other common formats include variable names, variable and value labels, and in some cases notes that can be extracted. And the variable-level summary statistics that are part of the metadata can be generated from the data files. Further, software applications used for capturing data like Survey Solutions from the World Bank or CsPro from the US Census Bureau can export variable metadata, including the variable names, the variable and value labels, and possibly the formulation of questions and the interviewers instructions when the software is used for conducting computer assisted personal interviews (CAPI). Survey Solutions and CsPro can export metadata in multiple formats, including the DDI Codebook. Multiple options exist to make the documentation of variables efficient. As much as possible, tedious manual curation of variable-level information should be avoided.
variables [Optional ; Repeatable]
The metadata elements we describe below apply independently to each variable in the dataset.
"variables": [
{
"file_id": "string",
"vid": "string",
"name": "string",
"labl": "string",
"var_intrvl": "discrete",
"var_dcml": "string",
"var_wgt": 0,
"loc_start_pos": 0,
"loc_end_pos": 0,
"loc_width": 0,
"loc_rec_seg_no": 0,
"var_imputation": "string",
"var_derivation": "string",
"var_security": "string",
"var_respunit": "string",
"var_qstn_preqtxt": "string",
"var_qstn_qstnlit": "string",
"var_qstn_postqtxt": "string",
"var_forward": "string",
"var_backward": "string",
"var_qstn_ivuinstr": "string",
"var_universe": "string",
"var_sumstat": [],
"var_txt": "string",
"var_catgry": [],
"var_std_catgry": {},
"var_codinstr": "string",
"var_concept": [],
"var_format": {},
"var_notes": "string"
}
]file_id[Required ; Not repeatable ; String]
A dataset can be composed of multiple data files. Thefile_idis the name of the data file that contains the variable being documented. This file name should correspond to afile_idlisted in thedata_filesection of the DDI.vid[Required ; Not repeatable ; String]
A unique identifier given to the variable. This can be a system-generated ID, such as a sequential number within each data file. Thevidis not the variable name.name[Required ; Not repeatable ; String]
The name of the variable in the data file. Thenameshould be entered exactly as found in the data file (not abbreviated or converted to upper or lower cases, as some software applications are case-sensitive). This information can be programmatically extracted from the data file. The variable name is limited to eight characters in some statistical analysis software such as SAS or SPSS.labl[Optional ; Not repeatable ; String]
All variables should have a label that provides a short but clear indication of what the variable contains. Ideally, all variables in a data file will have a different label. File formats like Stata or SPSS often contain variable labels. Variable labels can also be found in data dictionaries in software applications like Survey Solutions or CsPro. Avoid using the question itself as a label (specific elements are available to capture the literal question text; see below). Think of a label as what you would want to see in a tabulation of the variables. Keep in mind that software applications like Stata and others impose a limit to the number of characters in a label (often, 80).var_intrvl[Optional ; Not repeatable ; String]
This element indicates whether the intervals between values for the variable arediscreteorcontinuous.var_dcml[Optional ; Not repeatable ; String]
This element refers to the number of decimal points in the values of the variable.var_wgt[Optional ; Not repeatable ; Numeric]
This element, which applies to dataset from sample surveys, indicates whether the variable is a sample weight (value “1”) or not (value “0). Sample weights play an important role in the calculation of summary statistics and sampling errors, and should therefore be flagged.loc_start_pos[Optional ; Not repeatable ; Numeric]
The starting position of the variable when the data are saved in an ASCII fixed-format data file.loc_end_pos[Optional ; Not repeatable ; Numeric]
The end position of the variable when the data are saved in an ASCII fixed-format data file.loc_width[Optional ; Not repeatable ; Numeric]
The length of the variable (the maximum number of characters used for its values) in an ASCII fixed-format data file.loc_rec_seg_no[Optional ; Not repeatable ; Numeric]
Record segment number, deck or card number the variable is located on.var_imputation[Optional ; Not repeatable ; String]
Imputation is the process of estimating values for variables when a value is missing. The element is used to describe the procedure used to impute values when missing.var_derivation[Optional ; Not repeatable ; String]
Used only in the case of a derived variable, this element provides both a description of how the derivation was performed and the command used to generate the derived variable, as well as a specification of the other variables in the study used to generate the derivation. Thevar_derivationelement is used to provide a brief description of this process. As full transparency in derivation processes is critical to build trust and ensure replicability or reproducibility, the information captured in this element will often not be sufficient. A reference to a document and/or computer program can in such case be provided in this element, and the document/scripts provided as external resources. For example, a variable “TOT_EXP” containing the annualized total household expenditure obtained from a household budget survey may be the result of a complex process of aggregation, de-seasonalization, and more. In such case, the information provided in thevar_derivationelement could be: “TOT_EXP was obtained by aggregating expenditure data on all goods and services, available in sections 4 to 6 of the household questionnaire. It contains imputed rental values for owner-occupied dwellings. The values have been deflated by a regional price deflator available in variable REG_DEF. All values are in local currency. Outliers have been fixed by imputation. Details on the calculations are available in Appendix 2 of the Report on Data Processing, and in the Stata program [generate_hh_exp_total.do].”var_security[Optional ; Not repeatable ; String]
This element is used to provide information regarding levels of access, e.g., public, subscriber, need to know.var_respunit[Optional ; Not repeatable ; String]
Provides information regarding who provided the information contained within the variable, e.g., head of household, respondent, proxy, interviewer.var_qstn_preqtxt[Optional ; Not repeatable ; String]
The pre-question texts are the instructions provided to the interviewers and printed in the questionnaire before the literal question. This does not apply to all variables. Do not confuse this with instructions provided in the interviewer’s manual.var_qstn_qstnlit[Optional ; Not repeatable ; String]
The literal question is the full text of the questionnaire as the enumerator is expected to ask it when conducting the interview. This does not apply to all variables (it does not apply to derived variables).var_qstn_postqtxt[Optional ; Not repeatable ; String]
The post-question texts are instructions provided to the interviewers, printed in the questionnaire after the literal question. Post-question can be used to enter information on skips provided in the questionnaire. This does not apply to all variables. Do not confuse this with instructions provided in the interviewer’s manual.
With the previous three elements, one should be able to understand how the question was formulated in a questionnaire. In the example below (extracted from the UNICEF Malawi 2006 MICS survey questionnaire), we find:a pre-question: “Ask this question ONLY ONCE for each mother/caretaker (even if she has more children).”
a literal question: “Sometimes children have severe illnesses and should be taken immediately to a health facility. What types of symptoms would cause you to take your child to a health facility right away?”
a post-question: “Keep asking for more signs or symptoms until the mother/caretaker cannot recall any additional symptoms. Circle all symptoms mentioned. DO NOT PROMPT WITH ANY SUGGESTIONS”

var_forward[Optional ; Not repeatable ; String]
Contains a reference to the IDs of possible following questions. This can be used to document forward skip instructions.var_backward[Optional ; Not repeatable ; String]
Contains a reference to IDs of possible preceding questions. This can be used to document backward skip instructions.var_qstn_ivuinstr[Optional ; Not repeatable ; String]
Specific instructions to the individual conducting an interview. The content will typically be entered by copy/pasting instructions in the interviewer’s manual (or in the CAPI application). In cases where the same instructions relate to multiple variables, repeat the same information in the metadata for all these variables. NOTE: In earlier version of the documentation, due to a typo, the element was namedvar_qstn_ivulnstr.var_universe[Optional ; Not repeatable ; String]
The universe at the variable level defines the population the question applied to. It reflects skip patterns in a questionnaire. This information can typically be copy/pasted from the survey questionnaire. Try to be as specific as possible. This information is critical for the analyst, as it explains why missing values may be found in a variable. In the example below (from the Malawi MICS 2006 survey questionnaire), the universe for questions ED1 to ED2 will be “Household members age 5 and above”, and the universe for Question ED3 will be “Household members age 5 and above who ever attended school or pre-school”.var_sumstat[Optional ; Repeatable]
The DDI metadata standard provides multiple elements to capture various summary statistics such as minimum, maximum, or mean values (weighted and un-weighted) for each variable (note that frequency statistics for categorical variables are reported invar_catgrydescribed below). The content of thevar_sumstatsection will be easy to fill out programmatically (using R or Python) or using a specialized DDI metadata editor, which can read the data file and generate the summary statistics.
"var_sumstat": [
{
"type": "string",
"value": null,
"wgtd": "string"
}
]type[Required ; Not repeatable ; String]
The type of statistics being shown: mean, median, mode, valid cases, invalid cases, minimum, maximum, or standard deviation.value[Required ; Not repeatable ; Numeric]
The value of the summary statistics mentioned intype.wgtd[Required ; Not repeatable ; String]
Indicates whether the statistics reported invalueare weighted or not (for variables in sample surveys). Enter “weighted” if weighted, otherwise leave this element empty.var_txt[Optional ; Not repeatable ; String]
This element provides a space to describe the variable in detail. Not all variables require a definition.var_catgry[Optional ; Repeatable]
Variable categories are the lists of codes (and their meaning) that apply to a categorical variable. This block of elements is used to describe the categories (code and label) and optionally capture their weighted and/or un-weighted frequencies.
"var_catgry": [
{
"value": "string",
"label": "string",
"stats": [
{
"type": "string",
"value": null,
"wgtd": "string"
}
]
}
]value[Required ; Not repeatable ; String]
The value here is the code assigned to a variable category. For example, a variable “Sex” could have value 1 for “Male” and value 2 for “Female”.
label[Required ; Not repeatable ; String]
The label attached to the code mentioned invalue.stats[Optional ; Repeatable]
This repeatable block of elements will contain the summary statistics for the category (not for the variable) being documented. This may include frequencies, percentages, or cross-tabulation results.
type[Required ; Not repeatable ; String]
The type of the summary statistic. This will usually befreqfor frequency.value[Required ; Not repeatable ; Numeric]
The value of the summary statistic, for the correspondingtype.wgtd[Optional ; Not repeatable ; String]
Indicates whether the statistic reported invalueare weighted or not (for variables in sample surveys). Enter “weighted” if weighted, otherwise leave this element empty.
var_std_catgry[Optional ; Not repeatable]
This element is used to indicate that the codes used for a categorical variable are from a standard international or other classification, like COICOP, ISIC, ISO country codes, etc.
"var_std_catgry": {
"name": "string",
"source": "string",
"date": "string",
"uri": "string"
}name[Required ; Not repeatable ; String]
The name of the classification, e.g. “International Standard Industrial Classification of All Economic Activities (ISIC), Revision 4”source[Required ; Not repeatable ; String]
The source of the classification, e.g. “United Nations”date[Required ; Not repeatable ; String]
The version (typically a date) of the classification used for the study.
uri[Required ; Not repeatable ; String]
A URL to a website where an electronic copy and more information on the classification can be obtained.var_codinstr[Optional ; Not repeatable ; String]
The coder instructions for the variable. These are any special instructions to those who converted information from one form to another (e.g., textual to numeric) for a particular variable.var_concept[Optional ; Repeatable]
The general subject to which the parent element may be seen as pertaining. This element serves the same purpose as the keywords and topic classification elements, but at the variable description level.
"var_concept": [
{
"title": "string",
"vocab": "string",
"uri": "string"
}
]title[Optional ; Not repeatable ; String]
The name (label) of the concept.
vocab[Optional ; Not repeatable ; String]
The controlled vocabulary, if any, from which the concept `title’ was taken.uri[Optional ; Not repeatable ; String]
The location for the controlled vocabulary mentioned in `vocab’.var_format[Optional ; Not repeatable]
The technical format of the variable in question.
"var_format": {
"type": "string",
"name": "string",
"note": "string"
}type[Optional ; Not repeatable ; String]
Indicates if the variable is numeric, fixed string, dynamic string, or date. Numeric variables are used to store any number, integer or floating point (decimals). A fixed string variable has a predefined length which enables the publisher to handle this data type more efficiently. Dynamic string variables can be used to store open-ended questions.name[Optional ; Not repeatable ; String]
In some cases may provide the name of the particular, proprietary format used.note[Optional ; Not repeatable ; String]
Additional information on the variable format.var_notesOptional ; Not repeatable ; String]
This element is provided to record any additional or auxiliary information related to the specific variable.
Example for two variables only:
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ...
),
data_files = list(
# ...
),
variables = list(
list(file_id = "",
vid = "",
name = "",
labl = "Main occupation",
var_intrvl = "discrete",
var_imputation = "",
var_respunit = "",
var_qstn_preqtxt = "",
var_qstn_qstnlit = "",
var_qstn_postqtxt = "",
var_qstn_ivulnstr = "",
var_universe = "",
var_sumstat = list(list(type = "", value = "", wgtd = "")),
var_txt = "",
var_forward = "",
var_catgry = list(list(value = "",
label = "",
stats = list(list(type = "", value = "", wgtd = ""),
list(type = "", value = "", wgtd = ""),
list(type = "", value = "", wgtd = "")),
list(value = "",
label = "",
stats = list(list(type = "", value = "", wgtd = ""),
list(type = "", value = "", wgtd = ""),
list(type = "", value = "", wgtd = "")),
var_std_catgry = list(),
var_codinstr = "",
var_concept = list(list(title = "", vocab = "", uri = "")),
var_format = list(type = "numeric", name = "")
),
list(file_id = "",
vid = "",
name = "V75_HH_CONS",
labl = "Household total consumption",
var_intrvl = "continuous",
var_dcml = "",
var_wgt = 0,
var_imputation = "",
var_derivation = "",
var_security = "",
var_respunit = "",
var_qstn_preqtxt = "",
var_qstn_qstnlit = "",
var_qstn_postqtxt = "",
var_qstn_ivulnstr = "",
var_universe = "",
var_sumstat = list(list(type = "", value = "", wgtd = "")),
var_txt = "",
var_codinstr = "",
var_concept = list(list(title = "", vocab = "", uri = "")),
var_format = list(type = "", name = "", value = ""),
var_notes = ""
)
),
# ...
)5.4.5 Variable groups
variable_groups [Optional ; Repeatable]
In a dataset, variables are grouped by data file. For the convenience of users, the DDI allows data curators to organize the variables into different, “virtual” groups to organize variables by theme, type of respondent, or any other criteria. Grouping variables is optional, and will not impact the way variables are stored in the data files. One variable can belong to more than a group, and a group of variables can contain variables from more than one data file. The variable groups do not necessarily have to cover all variables in the data files. Variable groups can also contain other variable groups.
"variable_groups": [
{
"vgid": "string",
"variables": "string",
"variable_groups": "string",
"group_type": "subject",
"label": "string",
"universe": "string",
"notes": "string",
"txt": "string",
"definition": "string"
}
]vgid[Optional ; Not repeatable ; String]
A unique identifier (within the DDI metadata file) for the variable group.variables[Optional ; Not repeatable ; String]
The list of variables (variable identifiers -vid) in the group. Enter a list with items separated by a space, e.g. “V21 V22, V30”.variable_groups[Optional ; Not repeatable ; String]
The variable groups (vgid) that are embedded in this variable group. Enter a list with items separated by a space, e.g. “VG2, VG5”.group_type[Optional ; Subject ; Not Repeatable]
The type of grouping of the variables. A controlled vocabulary should be used. The DDI proposes the following vocabulary: {section, multipleResp, grid, display, repetition, subject, version, iteration, analysis, pragmatic, record, file, randomized, other}. A description of the groups can be found in this document by W. Thomas, W. Block, R. Wozniak and J. Buysse.label[Optional ; Not repeatable ; String]
A short description of the variable group.universe[Optional ; Not repeatable ; String]
The universe can be a population of individuals, households, facilities, organizations, or others, which can be defined by any type of criteria (e.g., “adult males”, “private schools”, “small and medium-size enterprises”, etc.).notes[Optional ; Not repeatable ; String]
Used to provide additional information about the variable group.txt[Optional ; Not repeatable ; String]
A more detailed description of variable group than the one provided inlabel.definition[Optional ; Not repeatable ; String]
A brief rationale for the variable grouping.
my_ddi <- list(
doc_desc = list(
# ...
),
study_desc = list(
# ...
),
data_files = list(
# ...
),
variables = list(
# ...
),
variable_groups = list(
list(vgid = "vg01",
variables = "",
variable_groups = "",
group_type = "subject",
label = "",
universe = "",
notes = "",
txt = "",
definition = ""
),
list(vgid = "vg02",
variables = "",
variable_groups = "",
group_type = "subject",
label = "",
universe = "",
notes = "",
txt = "",
definition = ""
)
),
# ...
)5.4.6 Provenance
provenance [Optional ; Repeatable]
Metadata can be programmatically harvested from external catalogs. The provenance group of elements is used to store information on the provenance of harvested metadata, and on alterations that may have been made to the harvested metadata. These elements are NOT part of the DDI metadata standard.
"provenance": [
{
"origin_description": {
"harvest_date": "string",
"altered": true,
"base_url": "string",
"identifier": "string",
"date_stamp": "string",
"metadata_namespace": "string"
}
}
]origin_description[Required ; Not repeatable]
Theorigin_descriptionelements are used to describe when and from where metadata have been extracted or harvested.harvest_date[Required ; Not repeatable ; String]
The date and time the metadata were harvested, entered in ISO 8601 format.altered[Optional ; Not repeatable ; Boolean]
A boolean variable (“true” or “false”; “true by default) indicating whether the harvested metadata have been modified before being re-published. In many cases, the unique identifier of the study (elementidnoin the Study Description / Title Statement section) will be modified when published in a new catalog.base_url[Required ; Not repeatable ; String]
The URL from where the metadata were harvested.identifier[Optional ; Not repeatable ; String]
The unique dataset identifier (idnoelement) in the source catalog. When harvested metadata are re-published in a new catalog, the identifier will likely be changed. Theidentifierelement inprovenanceis used to maintain traceability.date_stamp[Optional ; Not repeatable ; String]
The date stamp (in UTC date format) of the metadata record in the originating repository (this should correspond to the date the metadata were last updated in the source catalog).metadata_namespace[Optional ; Not repeatable ; String]
@@@@@@@
5.4.8 LDA topics
lda_topics [Optional ; Not repeatable]
"lda_topics": [
{
"model_info": [
{
"source": "string",
"author": "string",
"version": "string",
"model_id": "string",
"nb_topics": 0,
"description": "string",
"corpus": "string",
"uri": "string"
}
],
"topic_description": [
{
"topic_id": null,
"topic_score": null,
"topic_label": "string",
"topic_words": [
{
"word": "string",
"word_weight": 0
}
]
}
]
}
]We mentioned in Chapter 1 the importance of producing rich metadata, and the opportunities that machine learning offers to enrich (or “augment”) metadata in a largely automated manner. One application of machine learning, more specifically of natural language processing, to enrich metadata related to publications is the topic extraction using Latent Dirichlet Allocation (LDA) models. LDA models must be trained on large corpora of documents. They do not require any pre-defined taxonomy of topics. The approach consists of “clustering” words that are likely to appear in similar contexts (the number of “clusters” or “topics” is a parameter provided when training a model). Clusters of related words form “topics”. A topic is thus defined by a list of keywords, each one of them provided with a score indicating its importance in the topic. Typically, the top 10 words that represent a topic will be used to describe it. The description of the topics covered by a document (in this case, the “document” is a compilation of elements from the dataset metadata) can be indexed to improve searchability (possibly in a selective manner, by setting thresholds on the topic shares and word weights).
Once an LDA topic model has been trained, it can be used to infer the topic composition of any document. This inference will then provide the share that each topic represents in the document. The sum of all represented topics is 1 (100%).
The metadata element lda_topics is provided to allow data curators to store information on the inferred topic composition of the documents listed in a catalog. Sub-elements are provided to describe the topic model, and the topic composition. The lda_topics element is NOT part of the DDI Codebook standard.
Important note: the topic composition of a document is specific to a topic model. To ensure consistency of the information captured in the lda_topics elements, it is important to make use of the same model(s) for generating the topic composition of all documents in a catalog. If a new, better LDA model is trained, the topic composition of all documents in the catalog should be updated.
The lda_topics element includes the following metadata fields:
model_info[Optional ; Not repeatable]
Information on the LDA model.
source[Optional ; Not repeatable ; String]
The source of the model (typically, an organization).author[Optional ; Not repeatable ; String]
The author(s) of the model.version[Optional ; Not repeatable ; String]
The version of the model, which could be defined by a date or a number.model_id[Optional ; Not repeatable ; String]
The unique ID given to the model.nb_topics[Optional ; Not repeatable ; Numeric]
The number of topics in the model (the number of topics to be extracted from a corpus is the key parameter of any LDA model).description[Optional ; Not repeatable ; String]
A brief description of the model.corpus[Optional ; Not repeatable ; String]
A brief description of the corpus on which the LDA model was trained.uri[Optional ; Not repeatable ; String]
A link to a web page where additional information on the model is available.
topic_description[Optional ; Repeatable]
The topic composition of the document.
topic_id[Optional ; Not repeatable ; String]
The identifier of the topic; this will often be a sequential number (Topic 1, Topic 2, etc.).topic_score[Optional ; Not repeatable ; Numeric]
The share of the topic in the document (%).topic_label[Optional ; Not repeatable ; String]
The label of the topic, if any (not automatically generated by the LDA model).topic_words[Optional ; Not repeatable]
The list of N keywords describing the topic (e.g., the top 5 words).
word[Optional ; Not repeatable ; String]
The word.word_weight[Optional ; Not repeatable ; Numeric]
The weight of the word in the definition of the topic. This is specific to the model, not to a document.
lda_topics = list(
list(
model_info = list(
list(source = "World Bank, Development Data Group",
author = "A.S.",
version = "2021-06-22",
model_id = "Mallet_WB_75",
nb_topics = 75,
description = "LDA model, 75 topics, trained on Mallet",
corpus = "World Bank Documents and Reports (1950-2021)",
uri = ""))
),
topic_description = list(
list(topic_id = "topic_27",
topic_score = 32,
topic_label = "Education",
topic_words = list(list(word = "school", word_weight = "")
list(word = "teacher", word_weight = ""),
list(word = "student", word_weight = ""),
list(word = "education", word_weight = ""),
list(word = "grade", word_weight = "")),
list(topic_id = "topic_8",
topic_score = 24,
topic_label = "Gender",
topic_words = list(list(word = "women", word_weight = "")
list(word = "gender", word_weight = ""),
list(word = "man", word_weight = ""),
list(word = "female", word_weight = ""),
list(word = "male", word_weight = "")),
list(topic_id = "topic_39",
topic_score = 22,
topic_label = "Forced displacement",
topic_words = list(list(word = "refugee", word_weight = "")
list(word = "programme", word_weight = ""),
list(word = "country", word_weight = ""),
list(word = "migration", word_weight = ""),
list(word = "migrant", word_weight = "")),
list(topic_id = "topic_40",
topic_score = 11,
topic_label = "Development policies",
topic_words = list(list(word = "development", word_weight = "")
list(word = "policy", word_weight = ""),
list(word = "national", word_weight = ""),
list(word = "strategy", word_weight = ""),
list(word = "activity", word_weight = ""))
)
)
)5.4.9 Embeddings
embeddings [Optional ; Repeatable]
In Chapter 1 (section 1.n), we briefly introduced the concept of word embeddings and their use in implementation of semantic search tools. Word embedding models convert text (words, phrases, documents) into large-dimension numeric vectors (e.g., a vector of 100 or 200 numbers) that are representative of the semantic content of the text. In this case, the text would be a compilation of selected elements of the dataset metadata. The vectors are generated by submitting a text to a pre-trained word embedding model (possibly via an API).
The word vectors do not have to be stored in the document metadata to be exploited by search engines. When a semantic search tool is implemented in a catalog, the vectors will be stored in a database end processed by a tool like Milvus. A metadata element is however provided to store the vectors for preservation and sharing purposes. This block of metadata elements is repeatable, allowing multiple vectors to be stored. When using vectors in a search engine, it is critical to only use vectors generated by one same model. The embeddings element is NOT part of the DDI Codebook standard.
"embeddings": [
{
"id": "string",
"description": "string",
"date": "string",
"vector": { }
}
]The embeddings element contains four metadata fields:
- id [Optional ; Not repeatable ; String]
A unique identifier of the word embedding model used to generate the vector.
- description [Optional ; Not repeatable ; String]
A brief description of the model. This may include the identification of the producer, a description of the corpus on which the model was trained, the identification of the software and algorithm used to train the model, the size of the vector, etc.
- date [Optional ; Not repeatable ; String]
The date the model was trained (or a version date for the model).
- vector [Required ; Not repeatable ; Object] @@@@@@@@ do not offer options
The numeric vector representing the document, provided as an object (array or string).
[1,4,3,5,7,9]
5.4.10 Additional
additional [Optional ; Not repeatable]
The additional element is provided to allow users of the API to create their own elements and add them to the schema. It is not part of the DDI Codebook standard. All custom elements must be added within the element block; embedding them elsewhere in the schema would cause DDI schema validation to fail in NADA.
5.5 Generating and publishing DDI metadata
The DDI-Codebook metadata standard provides multiple elements to describe the variables in detail. This includes elements that are usually not found in data dictionaries, like summary statistics. Generating this information and manually capturing it in a DDI-compliant metadata file could be tedious. Indeed, some datasets contains hundreds or even thousands of variables. Some of the metadata (list of variables, possibly variable and value labels, and summary statistics) can be automatically extracted from the data files. Specialized metadata editors, who can read the data files, extract metadata, and generate DDI-compliant output are thus the preferred option to document microdata. Other software have the capability to generate variable-level metadata in DDI-compliant, such as CsPro and Survey Solutions (CAPI applications). Stata and R scripts also provide solutions to generate variable-level metadata out of data files. We present some of these tools below.
5.5.1 Using the World Bank Metadata Editor
@@@ Update this whole section with proper screenshots and description
The World Bank Metadata Editor is compliant with the DDI-Codebook 2.5. It is an open source software. [@@@@@ not yet - wait for license] It is a flexible application that can also accommodate other standards and schemas such as the Dublin Core (for documents) and the ISO 19139 (for geospatial data).
When importing data files, variable-level metadata is automatically generated including variable names, summary statistics, and variable and value labels if available in the source data files. Additional variable-level metadata can then be added manually.
The Metadata Editor provides forms to enter all other related metadata using the DDI-Codebook 2.5 standard, including the study description and a description of external resources.

The World Bank Metadata Editor exports the metadata (for microdataset) in DDI-Codebook 2.5 format (XML) and in JSON format. Metadata related to external resources can be exported to a Dublin Core file. A transformation of the metadata files into a PDF document is also implemented.
5.5.2 Using R or Python
DDI-compliant metadata can also be generated and published in a NADA catalog programmatically. Programming languages like R and Python provides much flexibility to generate such metadata, including variable-level metadata.
We provide here and example where a dataset is available in Stata format. We use two data files from the Core Welfare Indicator Questionnaire (CWIQ) survey conducted in Liberia in 2007 (the full dataset has 12 data files; the extension of the script to the full dataset would be straightforward). One data file, named “sec_abcde_individual.dta”, contains individual-level variables. The other data file, named “sec_fgh_ _household.dta”, contains household-level variables. The content of the Stata files is as follows:
When generating the variable-level metadata, we want to extract the value labels from the data files, keeping the original [code - value label] pairs as they are in the original dataset. For example, if the Stata dataset has codes 1 = Male and 2 = Female for variable sex, we do not want them to be changed for example to 1 = Female and 2 = Male by the data import process. The import process in R packages do not always maintain the code/label pairs; some convert categorical data into factors and assign codes and value labels independently from the original coding.
# In http://catalog.ihsn.org/catalog/1523
library(nadar)
library(haven)
library(rlist)
library(stringr)
# ----------------------------------------------------------------------------------
my_keys <- read.csv("C:/confidential/my_API_keys.csv", header=F, stringsAsFactors=F)
set_api_key("my_keys[1,1")
set_api_url("https://.../index.php/api/")
set_api_verbose(FALSE)
# ----------------------------------------------------------------------------------
id = "LBR_CWIQ_2007"
setwd("D:/LBR_CWIQ_2007")
thumb = "liberia_cwiq.JPG" # This image will be used as a thumbnail
# The literal questions are only found in a PDF file; we extract them.
# If list of questions had been available in MS-Excel format of equivalent, we
# would import it from that file.
literal_questions = list(
b1 = "Is [NAME] male or female?",
b2 = "How long has [NAME] been away in the last 12 months?",
b3 = "What is [NAME]'s relationship to the head of household?",
b4 = "How old was [NAME] at last birthday?",
b5 = "What is [NAME]'s marital status?",
b6 = "Is [NAME]'s father alive?",
b7 = "Is [NAME]'s father living in the household?",
b8 = "Is [NAME]'s mother alive?",
b9 = "Is [NAME]'s mother living in the household?",
c1 = "Can [NAME] read and write in any language?",
c2 = "Has [NAME] ever attended school?",
c3 = "What is the highest grade [NAME] completed?",
c4 = "Did [NAME] attend school last year?",
c5 = "Is [NAME] currently in school?",
c6 = "What is the current grade [NAME] is attending?",
c7 = "Who runs the school [NAME] is attending?",
c8 = "Did [NAME] have any problems with school?",
c9 = "Why is [NAME] not currently in school?",
c10= "Why has [NAME] not started school?"
# Etc. (we do not include all questions in the example)
)
# Generate file-level and variable-level metadata for the two data files
list_data_files = c("sec_abcde_individual.dta", "sec_fgh_household.dta")
list_var = list()
list_df = list()
vno = 1
fno = 1
for (datafile in list_data_files) {
data <- read_dta(datafile)
# Generate file-level metadata
# Create a file identifier (sequential)
fid = paste0("F", str_pad(fno, 2, pad = "0"))
fno = fno + 1
# Add core metadata
case_n = nrow(data) # Nb of observations in the data file
var_n = length(data) # Nb of variables in the data file
df = list(file_id = fid,
file_name = datafile,
case_count = case_n,
var_count = var_n)
list_df = list.append(list_df, df)
# Generate variable-level metadata
for(v in 1:length(data)) {
# Create a variable identifier (sequential)
vid = paste0("V", str_pad(vno, 4, pad = "0"))
vno = vno + 1
# Variable name and literal question
vname = names(data[v])
question = as.character(literal_questions[vname])
if(is.null(question)) question = ""
# Extract the variable label (trim leading and trailing white spaces)
var_lab <- trimws(attr(data[[v]], 'label'))
if(is.null(var_lab)) var_lab = ""
# Variable-level summary statistics
vval = sum(!is.na(data[[v]]))
vmis = sum(is.na(data[[v]]))
vmin = as.character(min(data[[v]], na.rm = TRUE))
vmax = as.character(max(data[[v]], na.rm = TRUE))
vstats = list(
list(type = "valid", value = vval),
list(type = "system missing", value = vmis),
list(type = "minimum", value = vmin),
list(type = "maximum", value = vmax)
)
# Extract the (original) codes and value labels and calculate frequencies
freqs = list()
val_lab <- attr(data[[v]], 'labels')
if(!is.null(val_lab) & typeof(data[[v]]) != "character") {
freq_tbl = table(data[[v]])
for (i in 1:length(val_lab)) {
f = list(value = as.character(val_lab[i]),
labl = as.character(names(val_lab[i])),
stats = list(
list(type = "count",
value = sum(data[[v]] == val_lab[i], na.rm = TRUE)
)
)
)
freqs = list.append(freqs, f)
}
}
# Compile the variable-level metadata
list_v = list(
file_id = fid,
vid = vid,
name = vname,
labl = var_lab,
var_qstn_qstnlit = question,
var_sumstat = vstats,
var_catgry = freqs)
# Add to the list of variables already documented
list_var = list.append(list_var, list_v)
}
}
# Generate the DDI-compliant metadata
cwiq_ddi_metadata <- list(
doc_desc = list(
producers = list(
list(name = "WB consultants")
),
prod_date = "2008-02-19"
),
study_desc = list(
title_statement = list(
idno = id,
title = "Core Welfare Indicators Questionnaire 2007"
),
authoring_entity = list(
list(name = "Liberia Institute of Statistics and Geo_Information Services")
),
study_info = list(
coll_dates = list(
list(start = "2007-08-06", end = "2007-09-22")
),
nation = list(
list(name = "Liberia", abbreviation = "LBR")
),
abstract = "The Government of Liberia (GoL) is committed to producing a Poverty Reduction Strategy Paper (PSRP). To do this, the GoL will need to undertake an analysis of qualitative and quantitative sources to understand the nature of poverty ('Where are we?'); to develop a macro-economic framework, and conduct broad based and participatory consultations to choose objectives, define and prioritize strategies ('Where do we want to go? How far can we get?); and to develop a monitoring and evaluation system ('How will we know when we get there?). The analysis of the nature of poverty, the Poverty Profile, will establish the overall rate of poverty incidence, identifying the poor in relation to their location, habits, occupations, means of access to and use of government services, and their living standards in regard to health, education, nutrition. Given the capacity constraints it has been agreed that this information will be collected in a single visit survey using the Core Welfare Indicators Questionnaire (CWIQ) survey with an additional module to cover household income, expenditure and consumption. This will provide information to estimate welfare levels & poverty incidence, which can be combined and analyzed with the sectoral information from the main CWIQ questionnaire. While countries with more capacity usually do a household income, expenditure and consumption survey over 12 months, the single visit approach has been used in a number of countries (mainly in West Africa) fairly successfully.",
geog_coverage = "National"
),
method = list(
data_collection = list(
coll_mode = "face to face interview",
sampling_procedure = "The CWIQ survey will be carried out on a sample of 3,600 randomly selected households located in 300 randomly selected clusters. This was the same basic sample used by the 2007 Liberian DHS. However, for Monrovia, a new listing was carried out and new EAs were chosen and the sampled households were chosen from that list. For rural areas, the same EAs were used but a new sample selection of housholds was drawn. Any household that may have participated in the LDHS was systematically eliminated. Twelve (12) households were selected in each of the 300 EA using systematic sampling. The total number of households and number of EAs sampled in each County are given in the table below. (More on the Sampling under the External Resources).",
coll_situation = "On average, the interview process lasted about about 2 hours 45 minutes. The Income and Expenditure questionnaire alone took about 2 hours to complete. In many occasions, the questionnaire was completed in 2 sitting sessions."
)
)
),
# Information of data files
data_files = list_df,
# Information on variables
variables = list_var
)
# Publish the metadata in the NADA catalog
microdata_add(
idno = id,
repositoryid = "central",
access_policy = "licensed",
published = 1,
overwrite = "yes",
metadata = cwiq_ddi_metadata,
thumbnail = thumb
)
# Add links to data and documents
external_resources_add(
title = "Liberia, CWIQ 2007, Dataset in Stata 15 format",
idno = id,
dcdate = "2007",
language = "English",
country = "Liberia",
dctype = "dat/micro",
file_path = "LBR_CWIQ_2007_Stata15.zip",
description = "Liberia CWIQ dataset in Stata 15 format (2 data files)",
overwrite = "yes"
)
external_resources_add(
title = "Liberia, CWIQ 2007, Dataset in SPSS Windows format",
idno = id,
dcdate = "2007",
language = "English",
country = "Liberia",
dctype = "dat/micro",
file_path = "LBR_CWIQ_2007_Stata15.zip",
description = "Liberia CWIQ dataset in SPSS for Windows [.sav] format (2 data files)",
overwrite = "yes"
)
external_resources_add(
title = "CWIQ 2007 Questionnaire",
idno = id,
dcdate = "2007",
language = "English",
country = "Liberia",
dctype = "doc/ques",
file_path = "LCWIQ2007_.pdf",
overwrite = "yes"
)After running the script, the metadata (and links) are available in the NADA catalog.